总结的几个关键词:全球化,安全,生态,展望,大神
收看于 Biliibili 直播:

刘奇(CEO) Opening Keynote
正式开始之前,发生了一点点小意外,本地语音接入出现了问题,大概12分钟就恢复了。
4.0 发布
唐刘(首席架构师,TiDB 4.0 负责人)(产品内核和功能方面)
性能提升(zhihu 已读集群,单独集群达到 500TB,整个集群容量超过 1PB)
生态工具的改进
- tiup
- br(backup/restore)
- CDC: Change Data Capture
- Dashboard - Observability is coming!
- slow log → 性能优化
- 排查问题(日志定位)→日志聚合
- key visualizier tool : 实时收集不同区域,不同表的数据读写。
Feature
- SQL Plan Management(SPM):越跑越慢,索引走不上。它可以保证不会用错索引(或者说选择更差的索引)。
- 10GB Large Transaction:金融行业的夜间跑批操作(TiDB 4.0 以前不支持大事务),4.0 就很好支持了。
- Sequence: 发号器;
- Flashback:领导再也不担心运维删库跑路了。(drop 一张表,可以快速将表恢复到原状)
- Spill data to the disk: 大查询会导致 oom,中间结果集非常大,撑爆 TiDB 内存。保证千万不会挂掉。
- AutoRandom Key: 之前是 range partition 架构,顺序写入。让写入的时候可以分散压力。
- Cascading Placement Rules:两地三中心,(sql 就可以进行操作)
- Add/Drop Primary key:
- Case-Insensitive Collation: 支持 utf8mb4 utf8mb4_general_ci;
- Expression Index: 对于函数(表达式)添加索引。
Hello TiDB 5.0 !!!
预计 2021 2,3月份发布。
主要点:
- 主要会关注稳定性和性能。
- 降低 tidb 成本(混部,SATA 盘)
- 易用(工具易用,迁移数据易用,cloudnative 方面 k8s 化)
- 支持阿里云、UCloud
- 智能调度(弹性调度更加智能),通过dashboard 更好的发现问题
刘寅(TiDB as a service: TiDB cloud) DBaaS
到底 tidb cloud 是什么?
tidb 部署:pd → tikv → tidb → tiflash (部署步骤)
生产环境(还需要些什么呢?)我们来看看整个生态链:
es kibana prometheus grafana alert manager lightning br cdc lb: haproxy LVS
TiDB Cloud Service 怎么帮大家解决这些问题?
tidb cloud 产品这个月就可以试用。(10分钟完成账号注册,服务的生产级的部署)
现在支持 aws, Google Cloud ,简单的点点鼠标就可以构建一套 TiDB 集群。
支持的国家和地区:美国(🇺🇸)、日本(🇯🇵)、东南亚(新加坡🇸🇬)
三类套餐
- t1.tiny, tidb(2 vCPU, 2GB Mem), tikv(2 vCPU, 4GB Mem,50GB NVMe SSD)
- t1.standard, tidb(2 vCPU, 2GB Mem), tikv(2 vCPU, 4GB Mem,50GB NVMe SSD)
- t1.highcpu,
其他:
- h1.highcpu, tidb(8 vCPU, 16GB Mem), tikv(16 vCPU, 122GB Mem,? SSD)
计算规则
- 按集群及其节点收费。(按照分钟级片段计费)
- 数据传输
- 备份
- 计算周期(按月)
云数据库的安全性如何保证?
- VPC 绝对的隔离。(租户之间不共享网络)
- 快速连接:通过 SQL Shell 连接
- 认证机制:开启 TLS 1.2 特性
- 数据传输会进行加密,TDE
- 兼容MySQL 体系;
自动备份
全备、增备,后续会做到可持续备份(恢复某时点的数据快照)。
支付行为
使用第三方支付体系。
合规安全
SOC 2 - type 1(WIP), SOC 2 - type 2( 2021),GDPR, HIPAA, mtcs? PCI…
开源框架
k8s 去管理 k8s(?)
现在注册,可以有14天的免费集群
Cloud Ecosystem
- Amazon EMR
- confluent cloud
- snowflake
- S3
- DATADOG
云支持服务商
- Azure
- Aliyun
- UCloud
国内的云,为什么要先在国外的云上呢?
因为海外很多用户都是在云上,所以把 TiDB 上云(aws, gcp)也就是很强的诉求了。
申砾(工程团队技术VP,海外业务负责人):海外进展
TiDB's Scale-out at Global Scope
2015.9 第一个 commit,开源
5年时间过去。。。(从中国走向全球)
Product for Global
TiDB 4.0 + DBaaS : Cloud Native
云的能力帮我们做到了以前做不到的能力。(EC2 按需购买)
VLDB 2020 Accepted : TiDB: A Raft-based HTAP Database
TiDB Community
- 开发者(slack)
- 每月 sig meeting
两个 CNCF 项目
-
TiKV (cncf incubating project)
-
Chaos-Mesh(cncf 捐献流程中)
-
开源社区
Lighthouse
- 手机支付:Paypay zaloPay Top U.S Payment Company
- 在线视频:U-NEXT dailymotion hulu
- 电子商务:Shopee Top Online Travel Agent
NDA 的原因不能透露。
NDA: https://zh.wikipedia.org/zh-hans/保密协议
PingCAP University 4.0
包含英文版本。
什么时候开始的全球化?(从开源的第一天)
tidb 与闭源的关系,或者怎么看待?
tidb 是有一个有社区,有生态,在大家身边的数据库。(tiup 一分钟就玩起来)
看代码实现,修复自己遇到的各种问题。
一句话回答:TiDB 是大家的数据库。
崔秋:Empower Yourself in TiDB Community
聊一聊社区、产品。
玩在一起,聊在一起,吐槽它,让它更好。
TiDB 是由开发者来创造的。(1017 contributors, 9 commiter 7 reviewer 76 active contributors all over the world)
TiDB 4.0 GA(TiDB+TiKV)

怎么比较好的从零到一的参与呢?
- 15 Special Interest Group
- 21 Working Group
进阶路线:Contributor → Active Contributor → Reviewer → Commiter → Maintainer
Talent Plan
初衷:帮助大学生了解分布式数据库。
学习:680+, 覆盖高校:15+,结业人数:55+
Talent Plan 解决了什么问题?
- 系统地学习分布式系统
- 从零到一实现一个分布式数据库
直接点击前往:https://university.pingcap.com/talent-plan/
TiDB 内核专家=talent plan + tidb 源码解析系列 +?
2019年的社区组织
User Group 区分出来 Leader , co-leader , ambassador
连接用户 共建社区(2019.06.23):
- TUG 2019:北京/上海/杭州/西南/华南
- TUG 2020:金融 TUG/东南亚 TUG/ 北美 TUG(进行中)
更好的服务所有想要参与 tidb 的社区开发者。
社区驱动
TiDB In Action base 4.0:
- 48 hours
- 102 作者
- 199 pull request
帮助 TiDB 4.0 版本测试
- 用户:转转
- 个人:manuel rigger/ wluckdog
https://asktug.com https://university.pingcap.com/
TiDB DBAs are wanted
查看 拉勾网(Slides 上一个笔误哦~)

TIDB 服务专家=asktug + pingcap university + ?
黄东旭(CTO):TiDB 下一步技术 Roadmap 展望
本次分享主要是围绕着”玄学“展开。
自称是一个文艺青年,但是想要把复杂、抽象的东西跟艺术和美融合在一起。
喜讯
本科毕业的民间科学家提交了 VLDB 2020 .
评价:the paper is going to start a new line of research and products.

模仿
欧几里得《几何原本》,《三体》
几条公理
- 数据是无穷无尽的,但是人的精力是有限的
- 几乎任何数据都是有价值的(Google 是不删数据的)
- 数据的拥有成本终会小于数据本身的价值
- 摩尔定律失效了(分布式系统一定是未来)
- 快优于慢
推论① - 分布式系统是唯一的出路
oceanbese tpcc 连续两次打破世界纪录
推论② - 数据处理栈碎片化局面会结束
推论③ - 计算资源的交付将会标准化
- 云是对标准化计算资源集合的提供者(并不是狭隘的公有云、私有化、混合云)
- 云会是计算资源交付唯一渠道
- 云上服务的交付也会标准化
推论④ - 业务对于实时性的要求会越来越高
未来 workload 会是什么样子?
- HyperScale!
- 数据之间的关联会被充分探索
- Workload 的边界开始越来越模糊
- oltp 越来越复杂
- olap 越来越需要实时
未来的数据库怎么应对?
两个未来基本的数据库设计方向
- 系统适应 workload,而不是反之
- 可变型的数据库,自动根据负载重塑自身(电影:「终结者」)
- Self-Tuning ← Level 1
- Smart Data Placement ← Level 2
- Learned data structure, learned index ← Level 3
- 基于服务的系统设计
- 主流服务 API 逐步标准化
- S3
- SQL DB(RDS)
- Filesystem(EBS, EFS)
- KV
- 新一代的数据库是否能将这些
- 主流服务 API 逐步标准化
调度粒度决定了系统的灵活性
真正核心的是调度器。
kubernetes 会将基础能力标准化。
未来
支持全文检索(ES 作为 tidb 的外部索引?)
整个直播时长:3小时~
第二天 DevCon 活动
姚维(PingCAP TiDB 开源社区运营负责人):怎么样跟 1000 个开发者合作?
TiDB 23000 star 斜率都看得出来
1017 Contributors 3 maintainers 9 Committers 7 Reviewers 76 Active Contributors
TiDB 4.0 GA 31086 stars 6755 issues 18738 pull requests 15954 contributors
TiDB Challege Program (挑战赛)
第一届
165 注册人数(23 team,122 individual contributor)
TiDB Performance Challenge Program
GC 性能优化
作者:tabokie
分数:27000 分
第二届
162 注册人数(324 任务被领取,142 已完成)
ddl: support the operation of adding multi-columns
作者:gauss1314
分数:2996
抓bug大赛:
40 注册人数
发现 81 个bug:p0:7, p1: 39
Manuel Rigger From ETH Zurich(自研算法来找 bug)
(苏黎世博士后)
Cooperate With 1000+ Contributors
SIG 和 WG
How to contribute
- README CONTRIBUTION
- Learning materials
- Talent Plan
- Ask anything?
- Issues
- AskTUG
- Join SIG
How to participate in SIG?
- SIG list
- Know about SIG
- Meeting Notes
- Meeting Link
- Contribution Map
- Github
- SIG Project
- Release Project
- Milestone
- Join Slack Channel to communicate
- #everyone
- #sig-tiup
- #sig-xxx
- Create a new SIG
- Submit a PR by follwing the step
- Wait for PMC LGTM
展望未来
荣誉时刻
TiKV Maintainer
李道兵@京东云
陈付@一点资讯
孙晓光@知乎
TiKV Committer
庄天翼@阿里巴巴
聂殿辉@掌门科技
Best Contributor 2020
由 SIG Leader 投票产生
TennyZhuang
TiDB Usability Challenge Program
.* Team(TennyZhuang)
gauss1314 Team
SSebo Team
TiDB Bug hunting Program
Manuel rigger
wwar
章鱼烧
陈付(一点资讯):TiKV Contributor 的进阶之路- engine sig 方向
毕业于浙江大学
TiKV 在一点资讯上的使用
使用 RocksDB Merge Operator(Atomic Read-Modify-Write) 实现原子列 upsert
数据和业务在线迁移
TiKV 社区初接触
开启 titan engine 会导致 tikv-server 间歇性 core 重启
- titan 进行了 KV 分离,不支持 merge operator 特性导致
TIKV TITAN 和 RocksDB BlobDB 都由于 compaction 过程中触发的
基于 titan 的 level-merge GC 特性,设计了 merge operator 实现方案,减少 blob file 的更新问题。(PR 4095)(不具备通用性就没有合入主干 master 分支)
RawKV 性能优化
RawKV 链路优化
优化 tikv raw get 读流程,实现 direct local reader,减少 cpu context 切换,提升性能 4% (PR 4222)
对 tikv storage 和 coprocessor 的 readpool 进行改进,提升集群数据读取性能,p999 降低 20%(PR 4486, 4628)
RawKV 设计优化
- 将分片 hash 与基于 range 的 tikv 数据分布方式进行结合的方案,消除了热点读写问题
- 表预分裂和预分布,解决了初始数据导入集群数据分布不均造成的单盘打满问题,并减少写放大
- 表数据 multi-CF 物理隔离方案,并通过单表多 CF 减少 RocksDB 实例大小,提升读写性能
Engine SIG 介绍
Rust-rocksdb FFI 优化
- RocksDB 的 Rust 封装
- tikv/rust-rocksdb/pull/401
- tikv/rust-rocksdb/pull/402
- tikv/rust-rocksdb/pull/418
VerKV 提案和实现
解决 RawKV 无法增量备份、CDC、集群数据迁移和同步的问题。
VerKV 也会支持到 TiKV API 中,现有 TxnKV, RawKV
心路感想
和社区一期成长
- 开放
- 友善
- 极客
孙晓光(知乎):BigTable on TiKV
2020年4月中经历了异地机房的迁移。
BigTable & HBase
Google BigTable @ 2005
数据模型:Sparse Multidimensional Sorted Map
Apache HBase @ 2007
好:生态成熟
不太好:跨行事务/二级索引不完善
好:Tephra/Omid/Phoenix/Trafodion 生态工具完善事务、二级索引和SQL支持
不太好:组件多运维工作量大
Yet Another BigTable
Yet Another BigTable @ 2017 → 2019
BigTable 数据模型
中等数据规模 → 迅速膨胀
基于成熟组件 k8s、kafka、redis、MySQL → TiDB
Cache Through 缓存,数据最终一致
MySQL 集群:8台→18台
NewSQL 时代的 NoSQL
- Web Scale Dataset
- Non Relational
- Relaxed Consistency
Yet Another BigTable @ 2020
- ✅跨行事务/二级索引
- ✅Schema/Schema Free 混合数据模型
- 多协议访问
- 可选的一致性级别
- 全文检索
- 离线分析能力
Table Store (https://github.com/zhihu/zetta)
Native Data Model
Data Model for MySQL Protocol
开源
万继光:
团队简介
15个老师,100多个研究生
NVM KV 性能优化研究
研究背景
- 全球数据量爆发式增长
- 键值存储系统快速发展
- NVM(非易失性内存) 技术成熟:intel 发布了商用的NVM 存储介质 3D XPoint,读写性能接近 DRAM,且拥有非易失的特点。
TiKV 存储引擎 RocksDB
- 合并操作导致严重的写放大的问题;
- 合并操作(特别是L0-L1的合并)导致写性能波动问题;
L0-L1 大数据量合并(2.5-4.5GB)
粗粒度合并:因L0未排序,导致一次合并几乎涉及L0与L1的所有文件。
- 减少波动:采用 NVM 矩阵结构的 Matrix-Table
按行快速写入,按列细粒度合并;
- 减少写放大:扩大L0空间,降低层数,从而减少写放大;
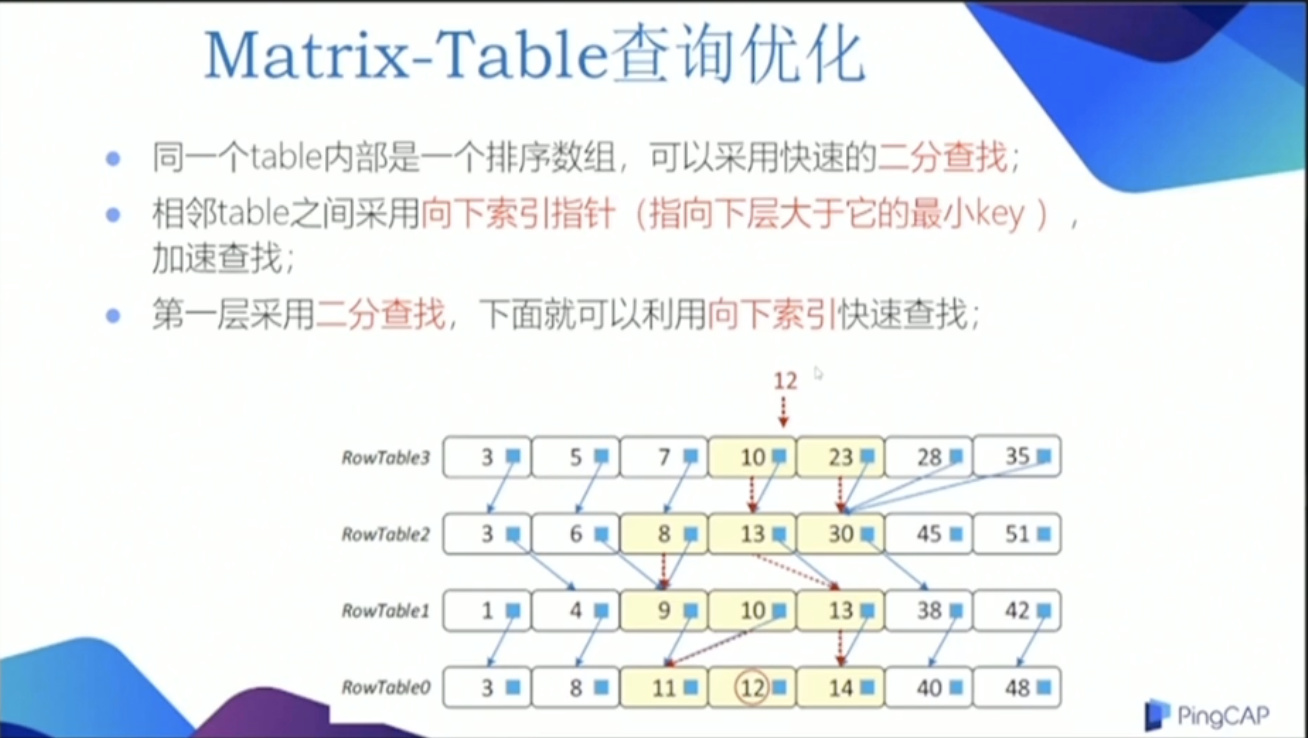
Matrix-Table 查询优化
- 二分查找;
- 向下索引指针(指向下层大于它的最小key),加速查找。
- 第一层采用二分查找,下面就可以利用向下索引查找;
太干了,没有太听懂。。。
按列细粒度合并
MatrixKV 采用 按列细粒度合并:减少一次合并的数据量;减少了写波动;
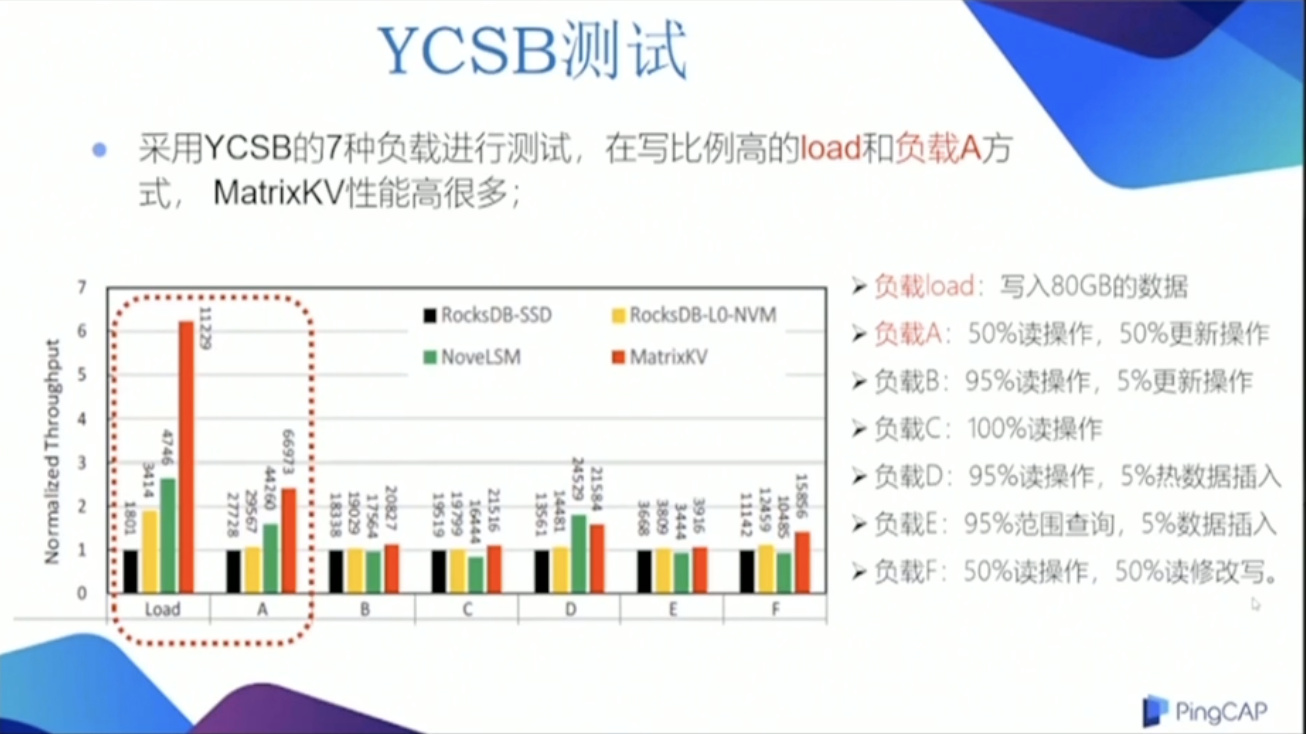
测试与分析

MatrixKV 的写性能波动明显优于小于其它3种方案
乣因为我们采用按列细粒度的合并操作;
论文1篇,专利1个
姚婷博士是第一作者:https://github.com/PDS-Lab/MatrixKV
AI 预测的弹性调度研究
研究背景
tikv 实现了弹性调度方案,采用按负载动态调整节点数;
存在调度滞后导致负载高峰冲突的问题;
研究目标
目标调度:提前调度
目标方案:AI预测+弹性调度
整体结构设计
应用负载智能预测;
调度方案设计;
推荐调度方案给 tikv 自身的调度系统;
调度方案分析
核心是选择:调度时机
高峰期之前把调度做完;
测试环境
模拟2种周期性变化负载;
历史负载预测未来负载曲线;
先的拟合度在 90% 以上;
调度前 QPS 峰值:7867
调度后 QPS 峰值:9787
提升1.24倍
延迟降低:158ms
KV 指令延迟降低:288ms
Talent Plan
华科-PingCAP 联合培训
第一阶段(线上)
第二阶段(线下)
第三阶段(PingCAP 实习)
丰富学生的知识体系
评价:干,清晰
李永坤(中国科学技术大学 | 计算机学院副教授):DiffKV 实践
KV 存储系统
数据存储格式
典型架构:LSM-Tree
主要问题:Compaction 引起的写放大,多层查找I/O引起的读放大
优化技术
- 放松有序性
- KV分离
- 索引优化
- 新型介质
DiffKV 动机
关键原因:Key 和 Value 的有序性
核心思想
差异化数据管理
- KV 的有序性差异化
- 异构数据的差异化管理
DiffKV 关键设计
小KV:LSM-tree, kv均有序同时保证写范围查询
中KV:增强LSM-tree,KV 分离保证写性能 范围查询:value 部分有序
大KV:KV 分离保证写性能垃圾回收开销
关键挑战
两颗 LSM-tree 的同步管理:松耦合机制
同步提升写性能,范围查询与单点查询性能,同时降低空间开销。
落地实现
实现功能:实现 level merge 功能,维护键值分离后的value有序性
为titan 设计了独立的空间回收逻辑
困难与经验
- 代码质量/系统正确性/开发效率
人员安排:基础+兴趣+组合
- 学生培养
工程能力:面向实际生产环境编写高质量代码/熟练各种工具
综合能力:协作开发/问题凝练/主导性思维
合作机制
自上而下-DiffKV
领域认识→科研问题→系统设计 → 落地验证
自下而上-分布式KV热点均衡
领域认识-系统设计-问题抽象← 实际问题
如何弥补研究成果与实际产品的差距。
合作体会(高校方)
企业:系统能力、实际问题、系统规模、真实数据
高校:创新空间、发散思维、宽松目标、育人为本
双方定位:共同兴趣点,共赢的诉求
合作方式:相对自由度,高度耦合
学生培养:能力培养更全面,综合素质要求更高

评语:语速好快。
庄天翼:参与 tikv 的心路历程
2018年毕业于清华大学
2018年 tidb hackathon UDF 支持
2019年 tidb hackathon Cross-DC TiDB (二等奖)
infra-meetup 118
(Active) Contributor
tikv #3374
Reviewer
medium #5866
leetcode discuss/672692/
Committer
Datetime format #14278 #14288
(改动了 81 个文件)
Mentee → Mentor
Toy → Production
Rust
(为工程化设计的)
Improvement
Impact++
为什么要贡献开源社区?
个人影响力的提升;
交流能使人进步;
评语:tql: 太强了
Manuel Rigger(苏黎世联邦理工学院):
奥地利,29岁
苏振东教授
Goal
logic bugs
Differential Testing
Larger Picture
- NoREC
- PQS(Pivoted Query Synthesis)
- TLP
茶歇驿站
一个可以让你停下来看一看,在茶歇之余给你帮助的小站,这里的内容主要是后端技术,个人管理,团队管理,以及其他个人杂想。