TiDB Hackathon 2018 学习到不少东西,希望明年再来。

注:待补充内容我将会补充到博客中。
简述
“pd ctl 天真学习机”
具体做法:用 naive bayes 模型来根据系统指标和人的 pd ctl 调用,来得到一个模型去根据系统指标去自动提供 pd ctl 调用的命令。
贝叶斯算法举例
贝叶斯模型可以用来干这种事:
比如一个妈妈根据天气预报来跟儿子在出们的时候叮嘱:
1
2
3
4
|
天气预报[ 晴, 温度: 28, 风力: 中 ], 妈妈会说 [好好玩]
天气预报[ 雨, 温度: 15, 风力: 低 ], 妈妈会说 [带上伞]
天气预报[ 阴, 温度: 02, 风力: 大 ], 妈妈会说 [多穿点]
...
|
把这些输入输入到贝叶斯模型里以后, 模型可以根据天气预报来输出:
1
2
|
天气预报[ 晴, 温度: 00, 风力中], 模型会说 [ 多穿点:0.7, 好好玩0.2, 带上伞0.1]
天气预报[ 雨, 温度: 10, 风力大], 模型会说 [ 带上伞:0.8, 多穿点0.1, 好好玩0.1]
|
这样通过一个妈妈的叮嘱就可以训练出一个也会根据天气预报给出叮嘱的模型。
初步想法
我们可以把一个模型单独的部署在一个 pod 里, 暴露一个 service ,然后集群上每次有人去调用 pd_ctl 的时候就在后台用 rest call 到模型服务上记录一下操作(叮嘱)和当前的系统指标(好比天气预报). 这样慢慢用一段时间以后,积累的操作多了以后,就可以打开某个自动响应,或者打开自动建议应该执行的命令的功能。
这样模型可以在某一组系统指标出现之前类似学习过的状态之后,给出相应的建议,当这些建议都很正确的时候直接让 pd 直接采纳,完全智能的自动化运作。
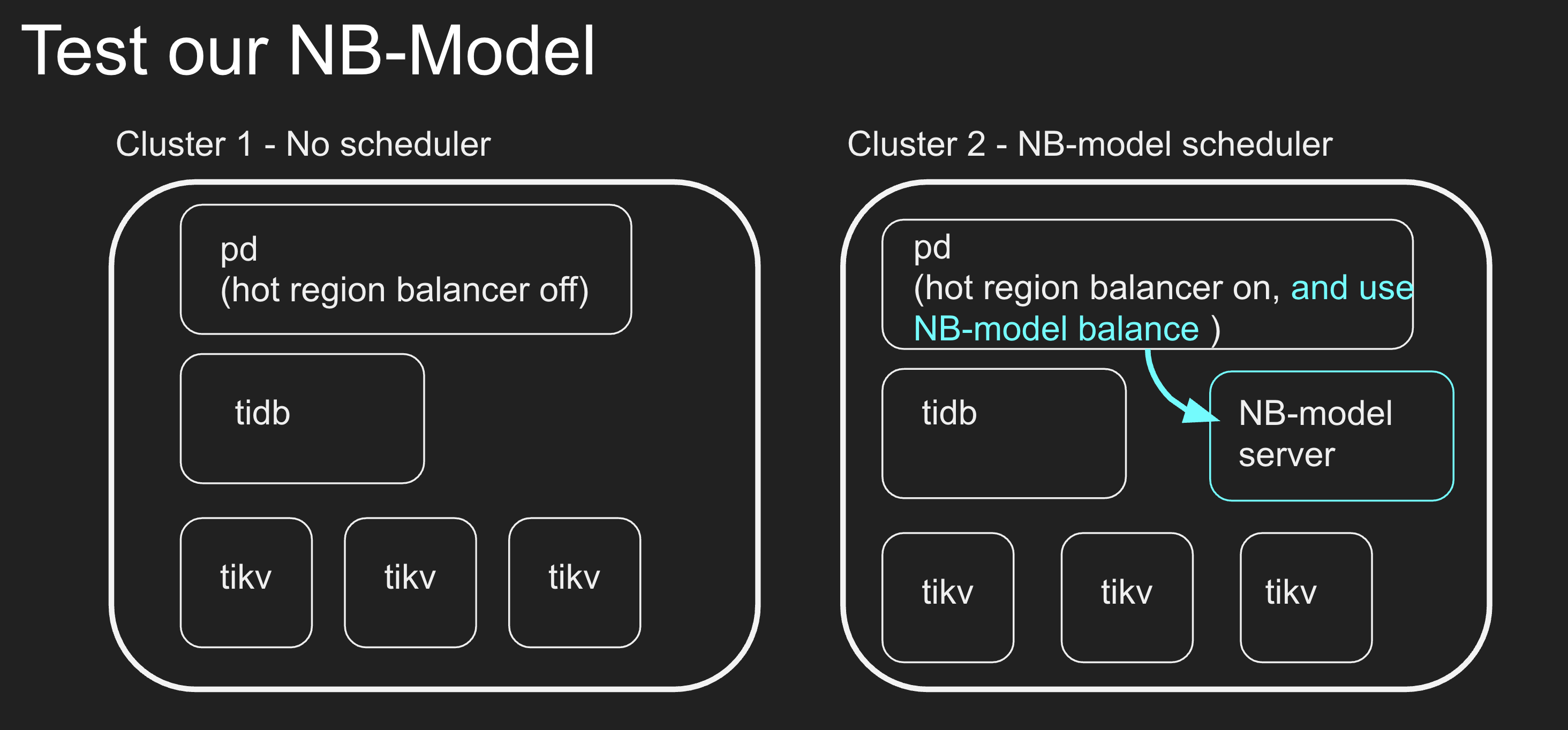
实际 Hackathon 方案
在跟导师交流探讨后发现,目前 PD 已经比较自动化了,很少需要人为介入进行操作,需要的时候也是比较复杂的场景,或者自动化运作比较慢的场景。
我们团队在跟多名导师的沟通交流下,将初步想法进行了一些调整:
- 从热点调度策略入手,用热点调度策略的数值去用 naive bayes 模型去训练他们,然后再根据这些数值再去模型中去获取建议值。
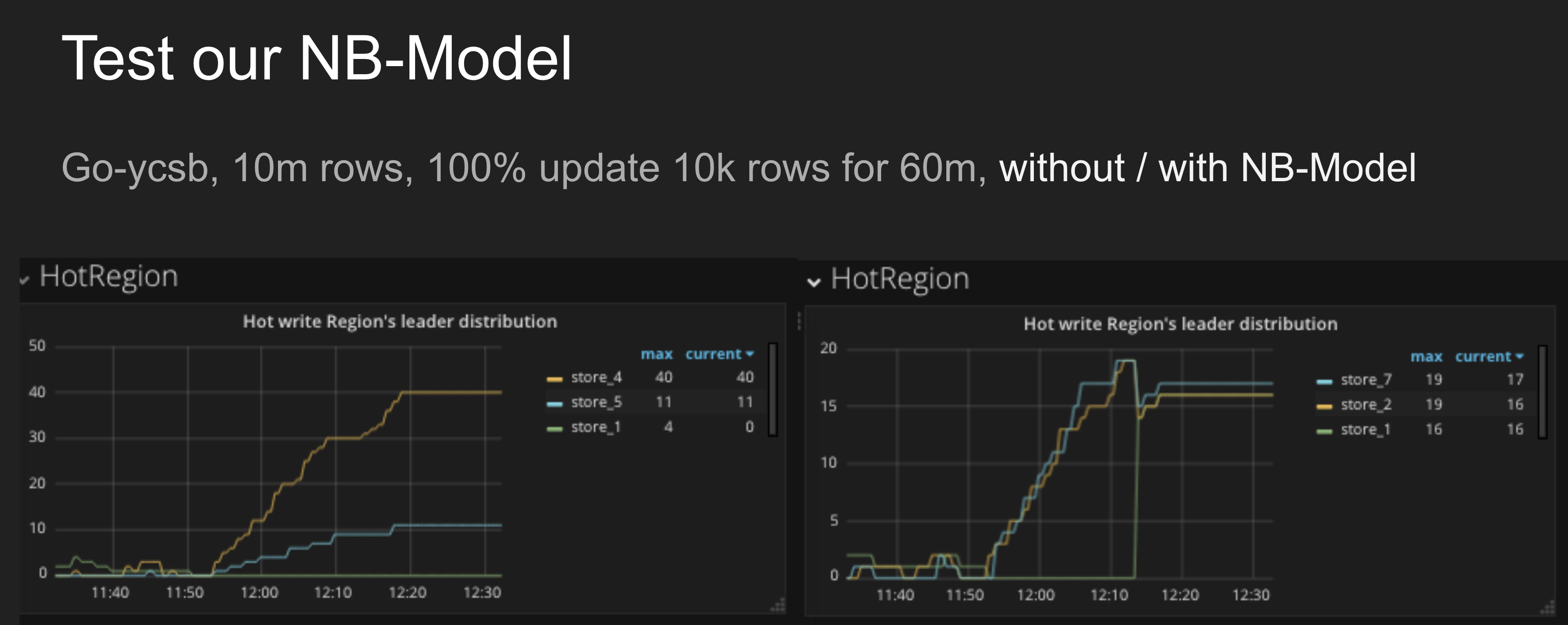
- 统计建议值和热点调度策略进行比较;(从开始的测试结果来看,大概有 70% 匹配,但是我们实测发现,使用我们模型的建议值去真正的调度,热点 region 还是非常均衡的)
- 三组对照试验:不进行调度,只打印调度数据;正常使用原来的热点调度策略;使用原来的热点调度策略的数值,但是使用模型训练的建议值进行实际调度;
一、Hackathon 回顾
首先,介绍一下我们团队(DSG),分别来自:丹麦、北京(山西)、广州。
D 先生是在比赛前一天早上到达北京的,我是比赛前一天晚上从广州出发,于比赛当日早上 6:38 才抵达北京的。
说实话,时差和疲惫对于参赛还是有一点影响的。
废话不多说,我就来回顾一下我的整个参赛过程。
- 比赛前一日 20:05 从广州南站出发,次日 6:38 抵达北京西站。
- 7:58 抵达地铁西小口


- 8:12 抵达比赛所在大厦:东升科技园 C-1 楼




- 8:40 跟 D 先生汇合,了解贝叶斯模型
- 9:20 DSG 团队成员全部集结完毕

- 10:00 比赛正式开始
10:00 Hacking Time: Trello 构建整个比赛分工、准备工作、需求分析
- 搭建 TiDB 集群(2套)
- 熟悉 TiDB 集群,实操 PD-CTL
- 12:17 午餐
- 13:00 Hacking Time: 熟悉 PD Command,贝叶斯模型,导师指导,本地 TiDB - 环境构建(坑),分析 PD 热点调度,剖析调度流程,模拟热点数据
- 18:20 外出用餐(芦月轩羊蝎子(西三旗店))【沾 D 先生的光去蹭吃蹭喝】
- 20:40 回到东升科技园
- 20:50 ~ 次日 1:10 Hacking Time: 模拟热点数据,实测调度上报和获取模型返回结果,本地测通调度参数上报和得到模型返回值
- 次日 1:10 ~ 5:50 会议室休息(在此期间,我的队友 D 先生,调好了模型,并将此模型通过 Docker 构建部署到 PD 机器上)
- 次日 5:50 Hacking Time: 将修改过的 PD 构建部署到线上服务器,并与 rust-nb-server 联调,实时上报和获取模型返回结果
- 次日 7:30 早餐
- 次日 8:00 正式联调
- 次日 9:00 抽签确定 Demo 时间
- 次日 9:00 ~ 12:00 Hacking Time: 联调,调优
- 次日 12:00 ~ 12:30 午餐时间

- 次日 12:30 ~ 14:00 Hacking Time: PPT,调优
- 次日 14:30 ~ 18:30 Demo Time(B 站直播)


- 次日 18:30 ~ 19:00 颁奖(B 站直播)


二、Hackathon 实操
1. 搭建 TiDB 集群
完全参考文档
测试 TiDB 集群,可能遇到的坑(MySQL 8 client On MacOSX):
2. 天真贝叶斯的服务接口
/model/service1 PUT 上报数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
{
"updates": [
[
"transfer leader from store 7 to store 2",
[
{
"feature_type": "Category",
"name": "hotRegionsCount1",
"value": "true"
},
{
"feature_type": "Category",
"name": "minRegionsCount1",
"value": "true"
},
{
"feature_type": "Category",
"name": "hotRegionsCount2",
"value": "true"
},
{
"feature_type": "Category",
"name": "minRegionsCount2",
"value": "true"
},
{
"feature_type": "Category",
"name": "srcRegion",
"value": "7"
}
]
],
[
"transfer leader from store 7 to store 1",
[
{
"feature_type": "Category",
"name": "hotRegionsCount1",
"value": "true"
},
{
"feature_type": "Category",
"name": "hotRegionsCount2",
"value": "true"
}
]
]
]
}
|
/model/service1 POST 获取模型结果:
输入参数:上报的参数
1
2
3
4
5
6
7
8
9
10
11
12
|
{
"predictions": [
{
"transfer leader from store 1 to store 2": 0.27432775221072137,
"transfer leader from store 1 to store 7": 0.6209064350448428,
"transfer leader from store 2 to store 1": 0.024587894827775753,
"transfer leader from store 2 to store 7": 0.01862719305134528,
"transfer leader from store 7 to store 1": 0.02591609468013258,
"transfer leader from store 7 to store 2": 0.03563463018518229
}
]
}
|
待补充…
3. PD 集群部署
首先将 pd-server 替换到集群所在 ansible/resources/bin 目录下,那如何让集群上的 PD 更新生效呢?
更新:
1
|
$ ansible-playbook rolling_update.yml --tags=pd
|
在实操过程中, 如果你在更新到一半的时候就关门了,可能会导致整个 PD 挂掉(非集群环境),可能是因为逻辑不严谨所导致的问题
直接停止了 ansible,导致 PD 集群机器节点有停止的情况,这个时候你可以通过以下命令启动它。
启动:
1
|
$ ansible-playbook start.yml --tags=pd
|
4. PD 调度
4.1 PD 之热点 Region 调度源码浅析
待补充…
4.2 取消热点数据调度
大家都以为可以通过配置来解决:(调度开关方法: 用 config set xxx 0 来关闭调度)
配置如下:(虽然找的地方错误了,但是错打错着,我们来到了 Demo Time:
1
2
3
4
5
6
|
config set leader-schedule-limit 0
config set region-schedule-limit 0
scheduler add hot-region-scheduler
config show
config set leader-schedule-limit 4
config set region-schedule-limit 8
|
实测发现,根本不生效,必须要改源代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func (h *balanceHotRegionsScheduler) dispatch(typ BalanceType, cluster schedule.Cluster) []*schedule.Operator {
h.Lock()
defer h.Unlock()
switch typ {
case hotReadRegionBalance:
h.stats.readStatAsLeader = h.calcScore(cluster.RegionReadStats(), cluster, core.LeaderKind)
// return h.balanceHotReadRegions(cluster) // 将这一行注释
case hotWriteRegionBalance:
h.stats.writeStatAsLeader = h.calcScore(cluster.RegionWriteStats(), cluster, core.LeaderKind)
h.stats.writeStatAsPeer = h.calcScore(cluster.RegionWriteStats(), cluster, core.RegionKind)
// return h.balanceHotWriteRegions(cluster) // 将这一行注释
}
return nil
}
|
但是,我们要的不是不调度,而只是不给调度结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
func (h *balanceHotRegionsScheduler) balanceHotReadRegions(cluster schedule.Cluster) []*schedule.Operator {
// balance by leader
srcRegion, newLeader := h.balanceByLeader(cluster, h.stats.readStatAsLeader)
if srcRegion != nil {
schedulerCounter.WithLabelValues(h.GetName(), "move_leader").Inc()
// step := schedule.TransferLeader{FromStore: srcRegion.GetLeader().GetStoreId(), ToStore: newLeader.GetStoreId()} // 修改为不返回值或者返回 _
_ = schedule.TransferLeader{FromStore: srcRegion.GetLeader().GetStoreId(), ToStore: newLeader.GetStoreId()}
// return []*schedule.Operator{schedule.NewOperator("transferHotReadLeader", srcRegion.GetID(), srcRegion.GetRegionEpoch(), schedule.OpHotRegion|schedule.OpLeader, step)} // 注释这一行,并 return nil
return nil
}
// balance by peer
srcRegion, srcPeer, destPeer := h.balanceByPeer(cluster, h.stats.readStatAsLeader)
if srcRegion != nil {
schedulerCounter.WithLabelValues(h.GetName(), "move_peer").Inc()
return []*schedule.Operator{schedule.CreateMovePeerOperator("moveHotReadRegion", cluster, srcRegion, schedule.OpHotRegion, srcPeer.GetStoreId(), destPeer.GetStoreId(), destPeer.GetId())}
}
schedulerCounter.WithLabelValues(h.GetName(), "skip").Inc()
return nil
}
......
func (h *balanceHotRegionsScheduler) balanceHotWriteRegions(cluster schedule.Cluster) []*schedule.Operator {
for i := 0; i < balanceHotRetryLimit; i++ {
switch h.r.Int() % 2 {
case 0:
// balance by peer
srcRegion, srcPeer, destPeer := h.balanceByPeer(cluster, h.stats.writeStatAsPeer)
if srcRegion != nil {
schedulerCounter.WithLabelValues(h.GetName(), "move_peer").Inc()
fmt.Println(srcRegion, srcPeer, destPeer)
// return []*schedule.Operator{schedule.CreateMovePeerOperator("moveHotWriteRegion", cluster, srcRegion, schedule.OpHotRegion, srcPeer.GetStoreId(), destPeer.GetStoreId(), destPeer.GetId())} // 注释这一行,并 return nil
return nil
}
case 1:
// balance by leader
srcRegion, newLeader := h.balanceByLeader(cluster, h.stats.writeStatAsLeader)
if srcRegion != nil {
schedulerCounter.WithLabelValues(h.GetName(), "move_leader").Inc()
// step := schedule.TransferLeader{FromStore: srcRegion.GetLeader().GetStoreId(), ToStore: newLeader.GetStoreId()} // 修改为不返回值或者返回 _
_ = schedule.TransferLeader{FromStore: srcRegion.GetLeader().GetStoreId(), ToStore: newLeader.GetStoreId()}
// return []*schedule.Operator{schedule.NewOperator("transferHotWriteLeader", srcRegion.GetID(), srcRegion.GetRegionEpoch(), schedule.OpHotRegion|schedule.OpLeader, step)} // 注释这一行,并 return nil
return nil
}
}
}
schedulerCounter.WithLabelValues(h.GetName(), "skip").Inc()
return nil
}
|
当修改了 PD 再重新编译得到 pd-server,将其放到
tidb-ansible/resources/bin/pd-server 并替换原来的文件,然后执行
ansible-playbook rolling_update.yml --tags=pd,即可重启 pd-server 服务。
在调优的过程中发现,当前 hot-region-scheduler 的调度时对于目标机器的选择,存在不是最优的,代码如下:
https://github.com/pingcap/pd/blob/master/server/schedulers/hot_region.go#L374
简述:循环遍历 candidateStoreIDs 的时候,如果满足条件有多台,那么最后一个总会覆盖前面已经存储到 destStoreID 里面的数据,最终我们拿到的 destStoreID 有可能不是最优的。
https://github.com/pingcap/pd/issues/1359
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// selectDestStore selects a target store to hold the region of the source region.
// We choose a target store based on the hot region number and flow bytes of this store.
func (h *balanceHotRegionsScheduler) selectDestStore(candidateStoreIDs []uint64, regionFlowBytes uint64, srcStoreID uint64, storesStat core.StoreHotRegionsStat) (destStoreID uint64) {
sr := storesStat[srcStoreID]
srcFlowBytes := sr.TotalFlowBytes
srcHotRegionsCount := sr.RegionsStat.Len()
var (
minFlowBytes uint64 = math.MaxUint64
minRegionsCount = int(math.MaxInt32)
)
for _, storeID := range candidateStoreIDs {
if s, ok := storesStat[storeID]; ok {
if srcHotRegionsCount-s.RegionsStat.Len() > 1 && minRegionsCount > s.RegionsStat.Len() {
destStoreID = storeID
minFlowBytes = s.TotalFlowBytes
minRegionsCount = s.RegionsStat.Len()
continue // 这里
}
if minRegionsCount == s.RegionsStat.Len() && minFlowBytes > s.TotalFlowBytes &&
uint64(float64(srcFlowBytes)*hotRegionScheduleFactor) > s.TotalFlowBytes+2*regionFlowBytes {
minFlowBytes = s.TotalFlowBytes
destStoreID = storeID
}
} else {
destStoreID = storeID
return
}
}
return
}
|
4.3 PD 重要监控指标详解之 HotRegion:
- Hot write Region's leader distribution:每个 TiKV 实例上是写入热点的 leader 的数量
- Hot write Region's peer distribution:每个 TiKV 实例上是写入热点的 peer 的数量
- Hot write Region's leader written bytes:每个 TiKV 实例上热点的 leader 的写入大小
- Hot write Region's peer written bytes:每个 TiKV 实例上热点的 peer 的写入大小
- Hot read Region's leader distribution:每个 TiKV 实例上是读取热点的 leader 的数量
- Hot read Region's peer distribution:每个 TiKV 实例上是读取热点的 peer 的数量
- Hot read Region's leader read bytes:每个 TiKV 实例上热点的 leader 的读取大小
- Hot read Region's peer read bytes:每个 TiKV 实例上热点的 peer 的读取大小
本次我们只 hack 验证了 Write Region Leader 这部分,所以我们重点关注一下监控和问题:
- Hot write Region's leader distribution
监控数据有一定的延时(粗略估计1-2分钟)
5. 模拟热点数据
修改 tidb-bench 的 Makefile#load 模块对应的主机地址,然后执行 make tbl, make load 即可往服务器 load 数据了。
注意,这里你也需要进行一些配置修改:--default-character-set utf8
犯的错:受限于本地-服务器间网络带宽,导入数据很慢。
1
|
$ ./go-ycsb run mysql -p mysql.host=10.9.x.x -p mysql.port=4000 -p mysql.db=test1 -P workloads/workloada
|
注:go-ycsb 支持 insert,也支持 update,你可以根据你的需要进行相对应的调整 workloada#recordcount 和 workloada#operationcount 参数。
6. 本地构建 rust-nb-server
rust 一天速成…
Demo Time 的时候听好几个团队都说失败了。我以前也尝试过,但是被编译的速度以及耗能给击败了。
环境都可以把你 de 自信心击溃。
1
2
3
|
rustup install nightly
cargo run
...
|
Mac 本地打包 Linux 失败:缺少 std 库,通过 Docker 临时解决。
7. 导师指导
从比赛一开始,导师团就非常积极和主动,直接去到每个项目组,给予直接指导和建议,我们遇到问题去找导师时,他们也非常的配合。
导师不仅帮我们解决问题(特别是热点数据构建,包括对于代码级别的指导),还跟我们一起探讨课题方向和实际可操作性,以及可以达到的目标。
非常感谢!!!
我们的准备和主动性真的不足,值得反思–也希望大家以后不要怕麻烦,有问题就大胆的去问。
三、Hackathon Demo show
整个 Demo show 进行的非常顺利,为每一个团队点赞!而且很多团队的作品都让人尖叫,可想而知他们的作品是多么的酷炫和牛逼,印象中只有一个团队在 Demo 环境出现了演示时程序崩溃的问题(用Java Netty 基于 TiKV 做的 memcache(实现了大部分的协议))。
👍🐂
四、Hackathon 颁奖
遗憾!!!
我们 DSG 团队荣获三等奖+最佳创意两项大奖,但是很遗憾我未能跟团队一起分享这一刻。
因为我要赶着去火车站,所以在周日下午6点的时候,我跟队友和一些朋友道别后,我就去火车站了,后面几组的 Demo Show 也很非常遗憾未能参加。
得奖感言:
谢谢 DSG 团队,谢谢导师,谢谢评委老师,谢谢 PingCAP 给大家筹备了这么好的一次黑客马拉松比赛活动。
五、TiDB Hackathon 2018 总结
本次比赛的各个方面都做的完美,除了网络。
- 环境(一定要提前准备)—-这次被坑了不少时间和精力;
- 配置文档中有一些注意事项,一定要仔细阅读:ext4 必须要每台机器都更新;
- [10.9.97.254]: Ansible FAILED! => playbook: bootstrap.yml; TASK: check_system_optional : Preflight check - Check TiDB server's RAM; message: {“changed”: false, “msg”: “This machine does not have sufficient RAM to run TiDB, at least 16000 MB."} - 内存不足的问题
- 可以在执行的时候增加参数来避免
ansible-playbook bootstrap.yml --extra-vars "dev_mode=True"
- 如果磁盘挂载有问题,可以重新清除数据后再重新启动;
ansible-playbook unsafe_cleanup_data.yml (https://github.com/pingcap/docs/blob/master/op-guide/ansible-operation.md)
六、参考资料
- https://github.com/pingcap/pd
- tidb-bench tpch
- https://github.com/pingcap/go-ycsb
- Ansible 部署
- PD 重要监控指标详解
- 使用 TiDB-Ansible 升级 TiDB
- 在线代码格式化
- rust-nb-server
茶歇驿站
一个可以让你停下来看一看,在茶歇之余给你帮助的小站,这里的内容主要是后端技术,个人管理,团队管理,以及其他个人杂想。