这是一篇 Go 语言中下划线的用法分析总结。
讨论时间:2018-05-08 19:25 ~ 2018-05-08 20:00
(总结汇总耗时:3个多小时。)
以下源码分析来源于 Go 夜读微信群的一次代码讨论,我们先来看看这一行代码吧。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
...
func (littleEndian) Uint64(b []byte) uint64 {
_ = b[7] // bounds check hint to compiler; see golang.org/issue/14808
return uint64(b[0]) | uint64(b[1])<<8 | uint64(b[2])<<16 | uint64(b[3])<<24 |
uint64(b[4])<<32 | uint64(b[5])<<40 | uint64(b[6])<<48 | uint64(b[7])<<56
}
func (littleEndian) PutUint64(b []byte, v uint64) {
_ = b[7] // early bounds check to guarantee safety of writes below
b[0] = byte(v)
b[1] = byte(v >> 8)
b[2] = byte(v >> 16)
b[3] = byte(v >> 24)
b[4] = byte(v >> 32)
b[5] = byte(v >> 40)
b[6] = byte(v >> 48)
b[7] = byte(v >> 56) // panic: runtime error: index out of range
}
...
|
源码可点击 golang/encoding/binary/binary.go
这是 early bounds check to guarantee safety of writes below 注释的 commit。
直译:“早期检查以确保下面的写入安全”。
我们怎么理解这句话呢?
- _可以在编译期检查
- 怎么保证可以做到早期检查呢?
- 如果出现数组越界,会在编译期就不通过。
- 是不是单纯为了如果数组长度不够就提前报错返回,不进行后面的赋值操作了。
不确定究竟是为什么,所以大家还自己写代码来实测验证一下。
寻找答案
StackOverflow 有一个一摸一样的问题(他的问题写的非常完整,还给出了另外一种优化,并引发了他的更深刻的思考),以下是 Google 翻译,方便大家查看。
CodeA:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
package main
import "fmt"
func main() {
b := []byte{0, 1, 2, 3, 4, 5, 6}
var v uint64 = 0x0807060504030201
b[0] = byte(v)
b[1] = byte(v >> 8)
b[2] = byte(v >> 16)
b[3] = byte(v >> 24)
b[4] = byte(v >> 32)
b[5] = byte(v >> 40)
b[6] = byte(v >> 48)
b[7] = byte(v >> 56) // panic: runtime error: index out of range
fmt.Println(b)
}
|
b[7] 是会越界的,但是以上代码是可以通过编译的,只是在执行的时候会报错。
CodeB:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
package main
import "fmt"
func main() {
b := []byte{0, 1, 2, 3, 4, 5, 6}
var v uint64 = 0x0807060504030201
b[7] = byte(v >> 56) // panic: runtime error: index out of range
b[6] = byte(v >> 48)
b[5] = byte(v >> 40)
b[4] = byte(v >> 32)
b[3] = byte(v >> 24)
b[2] = byte(v >> 16)
b[1] = byte(v >> 8)
b[0] = byte(v)
fmt.Println(b)
}
|
在一开始 b[7] = byte(v >> 56) 写入数据时就 panic 了。
CodeC:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
package main
import "fmt"
func main() {
b := []byte{0, 1, 2, 3, 4, 5, 6}
var v uint64 = 0x0807060504030201
_ = b[7] // early bounds check to guarantee safety of writes below
b[0] = byte(v)
b[1] = byte(v >> 8)
b[2] = byte(v >> 16)
b[3] = byte(v >> 24)
b[4] = byte(v >> 32)
b[5] = byte(v >> 40)
b[6] = byte(v >> 48)
b[7] = byte(v >> 56)
fmt.Println(b)
}
|
通过 _ = b[7] 做了早期检查以确保下面的写入安全。
这个问题的作者抛出来两个问题:
- Q1: 在 Golang 中是否有必要进行早期检查以保证书写的安全性?
- Q2: 为了保证书写的安全性进行早期检查的话,哪一个样本代码更简洁和性能优化(速度)好些呢?样本代码A,B,C或…?
- 作者的回答: 我认为是 B: 因为它简洁并做了早期检查,不是吗?
回答:
1
2
3
4
5
6
7
8
9
10
11
|
问题1:在 Golang 中是否有必要进行早期检查以保证书写的安全性?
A1:这里的答案是“是和否”。一般来说,“否”,你通常不必在Go中插入边界检查,因为编译器会为你插入它们(这就是为什么当你尝试访问片段长度之外的内存位置时,你的示例会 panic)。但是,如果你正在执行多个写入操作(“是”),则需要插入像提供的示例一样的早期边界检查,以确保你不会只有一些写入成功,从而使你处于不良状态(或重构,如你在示例B中所做的那样,以便首次写入最大阵列,确保在任何写入操作成功之前发生恐慌)。
然而,这不是一个“Go 问题”,因为它是一个通用的错误类。在任何语言中如果你不进行边界检查(或者如果它是一种强制执行像 Go 一样的边界的语言的最高索引),写入操作就不安全。这也很大程度上取决于解决方案;在你发布的标准库的示例中,用户进行边界检查是有必要的。但是,在你发布的第二个示例中,用户边界检查不是必需的,因为代码可以像 B 一样写,其中编译器会在第一行插入边界检查。
问题2:为了保证书写的安全性进行早期检查的话,哪一个样本代码更简洁和性能优化(速度)好些呢?样本代码A,B,C或...?
A2:我认为是 B: 因为它简洁并做了早期检查,不是吗?
你是对的。在 B 中,编译器会在第一次写入时插入边界检查,保护其余的写入。因为你正在使用常量(7,6,... 0)对切片进行索引,编译器可以将边界检查从其余的写入中删除,因为它可以保证它们是安全的。
|
另外一个人的回答:
1
2
3
4
5
|
关于“写入安全性”的评论在这里有误导性。在开始时放置最高边界检查只是一个优化。如果你忽略它,行为将不会改变(或变成“不安全”),但是你可能会遭受多重边界检查而不是仅仅一次的性能损失,因为每个后续较高索引所需的最小限度增量。
如果评论中提到“保证写入安全”,这只是意味着它将保证编译器后续的写入操作是安全的,无需插入更多的边界检查。把它写出来不会使写入不安全,只会让编译器插入更多的边界检查。在任何情况下,编译器都不会产生不安全的内存访问。
在代码中插入这个假的早期边界检查是一个好主意,而不是不使用它或者重写代码来合法使用最高索引(如代码B中的代码),这是值得商榷的。只要它清楚为什么它在那里(例如,一个明智的和没有误导性的评论)我会说如果你想使用它,并找到它的好处。一般情况下,通过手动优化,未来的编译器优化可能会使其成为冗余或以其他方式改变其有效性。
|
Go 语言中下划线的用法总结
用在 import
1
2
3
4
5
6
7
|
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
_ "net/http/pprof"
)
...
|
pprof 和 MySQL 是常见用法。
它会引入包,会先调用包中的 init() 函数,这种使用方式仅让导入的包做初始化,而不使用包中其他函数。
往往这些 init() 函数里面注册了自己包里面的引擎,让外部可以方便的使用,比方说很多实现 database/sql 的引擎,在 init() 函数里面都是调用了 sql.Register(name string, driver driver.Driver) 注册自己,然后外部就可以使用了。
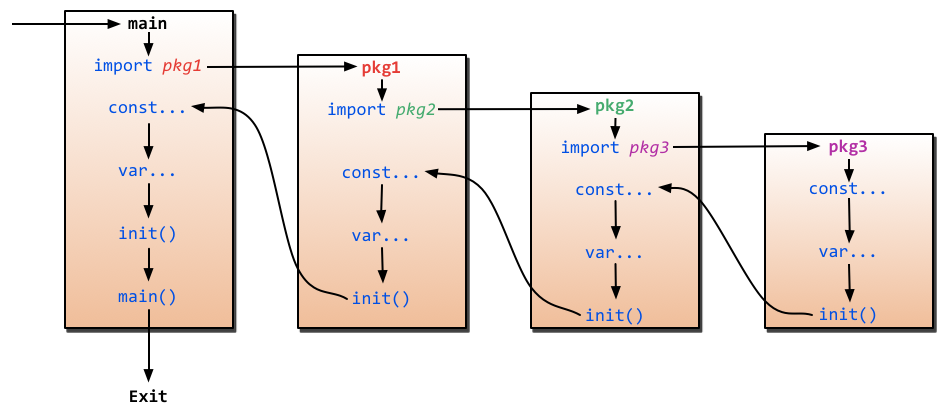
程序的初始化和执行都起始于 main 包,如果 main 包还导入了其它的包,那么就会在编译时将它们依次导入。有时一个包会被多个包同时导入,那么它只会被 导入一次(例如很多包可能都会用到fmt包,但它只会被导入一次,因为没有必要导入多次)。当一个包被导入时,如果该包还导入了其它的包,那么会先将其它 包导入进来,然后再对这些包中的包级常量和变量进行初始化,接着执行init函数(如果有的话),依次类推。等所有被导入的包都加载完毕了,就会开始对 main包中的包级常量和变量进行初始化,然后执行main包中的init函数(如果存在的话),最后执行main函数。下面是 init 的整个详细执行过程:
用在返回值
for _,v := range Slice{} // 表示丢弃索引值。
但是有些时候返回值不能丢弃,丢弃了会导致 memory leak,举个栗子:当你使用 http 请求第三方接口时,如果丢弃 response,那么 response 的 body 系统不会帮你 close,所以会导致很多的 time_wait,然后内存会缓慢上升。
_, err := func() // 单函数有多个返回值,用来获取某个特定的值,其他值不获取。
用在变量(接口实现检查)
首先我们来看 gin 框架的源代码 ResponseWriter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
type ResponseWriter interface {
http.ResponseWriter
http.Hijacker
http.Flusher
http.CloseNotifier
// Returns the HTTP response status code of the current request.
Status() int
// Returns the number of bytes already written into the response http body.
// See Written()
Size() int
// Writes the string into the response body.
WriteString(string) (int, error)
// Returns true if the response body was already written.
Written() bool
// Forces to write the http header (status code + headers).
WriteHeaderNow()
}
type responseWriter struct {
http.ResponseWriter
size int
status int
}
var _ ResponseWriter = &responseWriter{}
|
其中 ResponseWriter 为 interface,用来判断 responseWriter 结构体是否实现了 ResponseWriter,用作类型断言,如果 responseWriter 没有实现接口 ResponseWriter,则编译错误。
更多源码,点击前往:gin/response_writer.go
参考资料
- https://stackoverflow.com/questions/38548911/is-it-necessary-to-early-bounds-check-to-guarantee-safety-of-writes-in-golang
- Bounds Checking Elimination
- cmd/compile: unnecessary bounds checks are not removed #14808
茶歇驿站
一个可以让你停下来看一看,在茶歇之余给你帮助的小站,这里的内容主要是后端技术,个人管理,团队管理,以及其他个人杂想。