本文翻译自“如何在 Go 中正确使用 context.Context”,希望这一篇介绍能够让我们对于Go语言中的 context.Context 有更深一点的理解。
原文:https://medium.com/@cep21/how-to-correctly-use-context-context-in-go-1-7-8f2c0fafdf39
如何在 Go 中正确使用 context.Context
本文将讨论 Go 1.7 中的新库,context 库以及何时或如何正确使用它。 在开始介绍这篇文章有一些必须的阅读,有关这个库的演讲,以及通常是如何使用它的。你可以在 tip.golang.org 上阅读这个 context 库文档。
如何将 context 集成到你的 API?
将 Context 集成到 API 中时,要记住最重要的事情是它的目的是作为请求范围。 例如,沿着单个数据库查询是有意义的,但在数据库对象上没有意义。
目前有两种方法可将 Context 对象集成到你的 API 中:
- 函数调用的第一个参数
- 请求结构上的可选配置
有关第一个的例子,看 net 包的 Dialer.DialContext。这个函数执行一个正常的 Dial 操作,但是它能根据 context 对象将其取消。
|
|
有关集成 Context 的第二种方法的例子,看 net/http 包的 Request.WithContext
|
|
这将创建一个新的 Request 对象,该对象根据给定的 context 结束。
Context 应该流经你的程序
使用 Context 的一个很好的模型是它应该流过你的程序。想象一下河流或流水。这通常意味着你不想把它存储在结构体中的某个地方。你也不想把它放在很严格需要的地方。 Context 应该是一个接口,从函数传递到你的调用堆栈,根据需要进行扩展。 理想情况下,每个请求都会创建一个 Context 对象,并在请求结束时过期。
不存储 Context 的一个例外是当你需要将它放在一个纯粹用作通过通道传递的消息的结构中时。 这个在下面的例子中显示。
|
|
在这个例子中,我们通过将这个通用规则放在消息中来解决这个问题。然而,这是对 Context 的恰当使用,因为它仍流经程序,但是沿着通道而不是堆栈跟踪。
另请注意这里是如何使用 Context 的四个地方:
- 在处理器太满的情况下超时
- 让 q 知道它是否应该处理消息
- 超时 q 将消息发送回
newRequest() - 为了等待从 ProcessMessage 返回的响应,超时
newRequest()
所有阻塞/长时间操作应该是可取消的
当你取消用户取消长时间运行操作的能力时,你需要的时间长于用户想要的长度。随着 Go 1.7 进入标准库后的使用,它将很容易成为超时或结束早期长期运行操作的标准抽象。 如果你正在编写一个库并且你的函数可能被阻塞,那么这对于上下文来说是一个完美的用例。
在上面的例子,ProcessMessage 是
在上面的例子中,ProcessMessage是一个不会阻塞的快速操作,所以 context 显然是矫枉过正的。 然而,如果这是一个更长的操作,那么调用者使用 Context 会允许 newRequest 继续前进,如果计算时间太长的话。
Context.Value和请求范围值(警告)
Context 中最有争议的部分是值,它允许将任意值放入 Context 中。 来自原始博客文章的 Context.Value 的预期用途是请求范围值。 请求作用域值是从传入请求中的数据派生而来,并在请求结束时消失。 当请求在服务之间跳动时,这些数据通常在 RPC 调用之间维护。 我们首先尝试澄清什么是或不是请求范围值。
显而易见的请求范围数据可以是谁在提出请求(用户ID),他们如何进行(内部或外部),他们从何处做出(用户IP),以及这个请求应该有多么重要。
数据库连接不是请求范围值,因为它对整个服务器是全局的。 另一方面,如果它是一个具有关于当前用户的元数据的连接来自动填充字段,如用户ID或进行身份验证,那么它可能被视为请求范围。
如果 logger 位于服务器对象上或者是包的单例,则它不是请求范围。 但是,如果它包含有关谁发送请求的元数据,并且可能请求启用了调试日志记录,那么它将成为请求范围。
Unfortunately, request scoped data can encompass a large set of information since in some sense all the interesting data in the application comes from a request. This puts a broad definition on what could be included in Context.Value, which makes it easy to abuse. I personally have a more narrow view of what is appropriate in Context.Value and I’ll try to explain my position in the rest of this post.
不幸的是,请求范围数据可能包含大量信息,因为在某种意义上,应用程序中的所有有趣数据都来自请求。 这就对Context.Value中可能包含的内容提出了广泛的定义,从而使其易于滥用。 我个人对Context.Value中的适当内容有更加狭隘的看法,我会试着解释我在本文的其余部分中的立场。
Context.Value obscures your program’s flow
The real reason so many restrictions are placed on proper use of Context.Value is that it obscures expected input and output of a function or library. It is hated by many for the same reasons people hate singletons. Parameters to a function are clear, self sufficient documentation of what is required to make the function behave. This makes the function easy to test and reason about intuitively, as well as refactor later. For example, consider the following function that does authentication from Context.
如何正确使用Context.Value的真正原因在于它掩盖了期望的函数或库的输入和输出。 由于人们讨厌单身人士的相同原因,人们讨厌它。 一个函数的参数是清晰的,足以证明这个函数需要做什么。 这使得该功能易于直观地进行测试和推理,以及稍后进行重构。 例如,考虑从Context执行身份验证的以下功能。
|
|
When users call this function they only see that it takes a Context. But the required parts to knowing if a user is an Admin are clearly two things: an authentication service (in this case used as a singleton) and an authentication token. You can represent this as inputs and outputs like below.
当用户调用这个函数时,他们只会看到它需要一个Context。 但是知道用户是否是Admin的必要部分显然是两件事:认证服务(在本例中用作单例)和认证令牌。 您可以将其表示为输入和输出,如下所示。
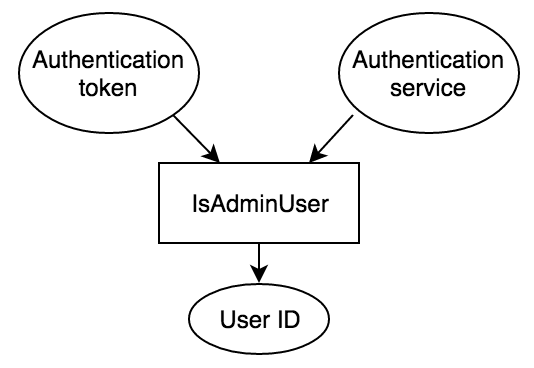
Let’s clearly represent this flow with a function, removing all singletons and Contexts.
让我们用一个函数清楚地表示这个流程,删除所有单例和上下文。
|
|
This function definition is now a clear representation of what is required to know if a user is an admin. This representation is also apparent to the user of the function and makes refactoring and reusing the function more understandable.
此功能定义现在清楚地表示了解用户是否为管理员所需的内容。 这种表示对于该函数的用户也是明显的,并且使该函数的重构和重用更易于理解。
Context.Value and the realities of large systems
I strongly empathize with the desire to shove items in Context.Value. Complex systems often have middleware layers and multiple abstractions along the call stack. Values calculated at the top of the call stack are tedious, difficult, and plain ugly to your callers if you have to add them to every function call between top and bottom to just propagate something simple like a user ID or auth token. Imagine if you had to add another parameter called “user ID” to dozens of functions between two calls in two different packages just to let package Z know about what package A found out? The API would look ugly and people would yell at you for designing it. GOOD! Just because you’ve taken that ugliness and obscured it inside Context.Value doesn’t make your API or design better. Obscurity is the opposite of good API design.
我强烈同情在Context.Value中推送项目的愿望。 复杂的系统通常沿着调用栈具有中间件层和多个抽象。 在调用堆栈顶部计算的值对您的调用者来说是单调乏味,困难和难以理解的,如果您必须将它们添加到顶部和底部之间的每个函数调用中,只传播一些简单的用户标识或身份验证令牌。 想象一下,如果你必须在两个不同包中的两个调用之间添加另一个名为“用户ID”的参数,才能让包Z知道包A发现了什么? 该API看起来很丑,人们会为你设计它而吼叫。 好! 只是因为你已经采取了这种丑陋的行为,并且在Context.Value中隐藏了它并不会让你的API或设计更好。 模糊不清与优秀的API设计相反。
Context.Value should inform, not control
Inform, not control. This is the primary mantra that I feel should guide if you are using context.Value correctly. The content of context.Value is for maintainers not users. It should never be required input for documented or expected results.
通知,而不是控制。 如果你正在使用context.Value,这是我认为应该引导的主要口头禅。 context.Value的内容是维护者而不是用户。 它不应该被要求输入文件或预期的结果。
To clarify, if your function can’t behave correctly because of a value that may or may not be inside context.Value, then your API is obscuring required inputs too heavily. Beyond documentation, there is also the expected behavior of your application. If the function, for example, is behaving as documented but the way your application uses the function has a practical behavior of needing something in Context to behave correctly, then it moves closer to influencing the control of your program.
One example of inform is a request ID. Generally these are used in logging or other aggregation systems to group requests together. The actual contents of a request ID never change the result of an if statement and if a request ID is missing it does nothing to modify the result of a function.
Another example that fits the definition of inform is a logger. The presence or lack of a logger never changes the flow of a program. Also, what is or isn’t logged is usually not documented or relied upon behavior in most uses. However, if the existence of logging or contents of the log are documented in the API, then the logger has moved from inform to control.
Another example of inform is the IP address of the incoming request, if the only purpose of this IP address is to decorate log messages with the IP address of the user. However, if the documentation or expected behavior of your library is that some IPs are more important and less likely to be throttled then the IP address has moved from inform to control because it is now required input, or at least input that alters behavior.
A database connection is a worst case example of an object to place in a context.Value because it obviously controls the program and is required input for your functions.
The golang.org blog post on context.Context is potentially a counter example of how to correctly use context.Value. Let’s look at the Search code posted in the blog.
为了澄清,如果你的函数由于可能存在或不存在于context.Value中的值而无法正确运行,那么你的API会使所需的输入过于模糊。除了文档之外,还有应用程序的预期行为。例如,如果函数的行为与文档相同,但应用程序使用该函数的方式具有需要Context中某些内容正确行为的实际行为,则它更接近于影响程序的控制。
通知的一个例子是请求ID。通常,这些用于日志记录或其他聚合系统中,以将请求分组在一起。请求ID的实际内容决不会改变if语句的结果,如果请求ID缺失,它不会修改函数的结果。
符合信息定义的另一个例子是记录器。记录器的存在或不存在不会改变程序的流程。此外,什么是或没有记录通常没有记录或依赖大多数用途的行为。但是,如果在API中记录了日志的存在或日志的内容,则记录器已从通知转移到控制。
另一个通知示例是传入请求的IP地址,如果此IP地址的唯一目的是用用户的IP地址修饰日志消息。但是,如果您的库的文档或预期行为是某些IP更重要且不太可能受到限制,那么IP地址已从通知转为控制,因为它现在是必需的输入或至少是改变行为的输入。
数据库连接是放置在上下文中的对象的最坏情况示例.Value是因为它明显控制程序并且是您的函数所需的输入。
关于context.Context的golang.org博客文章可能是如何正确使用context.Value的反例。我们来看看博客中发布的搜索代码。
|
|
The primary measuring stick is knowing how the existence of a userIP on the query changes the result of a request. If the IP is distinguished in a log tracking system so people can debug the destination server, then it purely informs and is OK. If the userIP being inside a request changes the behavior of the REST call or tends to make it less likely to be throttled, then it begins to control the likely output of Search and is no longer appropriate for Context.Value.
The blog post also mentions authorization tokens as something that is stored in context.Value. This clearly violates the rules of appropriate content in Context.Value because it controls the behavior of the function and is required input for the flow of your program. Instead, it is better to make tokens an explicit parameter or member of a struct.
主要的衡量标准是知道查询中用户IP的存在如何改变请求的结果。 如果在日志跟踪系统中区分IP以便人们可以调试目标服务器,那么它纯粹通知并且可以。 如果请求中的用户IP改变了REST调用的行为或者倾向于使其不太可能被限制,那么它开始控制搜索的可能输出并且不再适合于Context.Value。
该博文还提到授权令牌存储在context.Value中。 这显然违反了Context.Value中适当内容的规则,因为它控制着函数的行为,并且是程序流所需的输入。 相反,使令牌成为显式参数或结构成员会更好。
Does Context.Value even belong?
Context does two very different things: one of them times out long running operations and the other carries request scoped values. Interfaces in Go should be about describing behaviors an API wants. They should not be grab bags of functions that happen to often exist together. It is unfortunate that I’m forced to include behavior about adding arbitrary values to an object when all I care about is timing out runaway requests.
上下文做了两件非常不同的事情:其中一个超时长时间运行,另一个带有请求范围值。 Go中的接口应该是描述API所需的行为。 他们不应该抓住那些经常一起存在的功能。 不幸的是,当我所关心的是超时失控请求时,我不得不将任意值添加到对象的行为。
Alternatives to Context.Value
People often use Context.Value in a broader middleware abstraction. Here I’ll show how to stay inside this kind of abstraction while still not needing to abuse Context.Value. Let’s show some example code that uses HTTP middlewares and Context.Value to propagate a user ID found at the beginning of the middleware. Note Go 1.7 includes a context on the http.Request object. Also, I’m a bit loose with the syntax, but I hope the meaning is clear.
人们经常在更广泛的中间件抽象中使用Context.Value。 在这里我将展示如何留在这种抽象中,同时还不需要滥用Context.Value。 我们来展示一些使用HTTP中间件和Context.Value的示例代码来传播在中间件开始处找到的用户ID。 注意Go 1.7在http.Request对象上包含一个上下文。 另外,我的语法有点松散,但我希望它的含义很明确。
|
|
This is an example of how Context.Value is often used in middleware chains to setup propagating a userID along. The first middleware, addUserID, updates the context. It then calls the next handler in the middleware chain. Later the user id value inside the context is extracted and used. In large applications you could imagine these two functions being very far from each other.
Let’s now show how using the same abstraction we can do the same thing, but not need to abuse Context.Value.
这是中间件链中经常使用Context.Value设置传播用户ID的一个例子。 第一个中间件addUserID更新上下文。 然后它调用中间件链中的下一个处理程序。 稍后,上下文中的用户标识值将被提取并使用。 在大型应用程序中,您可以想象这两个功能相距甚远。
现在我们来演示如何使用相同的抽象我们可以做同样的事情,但不需要滥用Context.Value。
|
|
In this example, we can still use the same middleware abstractions and still have only the main function know about the chain of middleware, but use the UserID in a type safe way. The variable chainPartOne is the middleware chain up to when we extract the UserID. That part of the chain can then create the next part of the chain, chainWithAuth, using the UserID directly.
In this example, we can keep Context to just ending early long running functions. We have also clearly documented that struct UseUserID needs a UserID to behave correctly. This clear separation means that when people later refactor this code or try to reuse UseUserID, they know what to expect.
在这个例子中,我们仍然可以使用相同的中间件抽象,并且仍然只有主函数知道中间件链,但是以类型安全的方式使用UserID。 变量chainPartOne是我们提取UserID时的中间件链。 然后链的那部分可以直接使用UserID创建链的下一部分chainWithAuth。
在这个例子中,我们可以让Context刚刚结束早期的长时间运行的函数。 我们还清楚地记录了结构UseUserID需要用户ID正确行为。 这种清晰的分离意味着当人们稍后重构此代码或尝试重用UseUserID时,他们知道应该期待什么。
Why the exception for maintainers
I admit carving out an exception for maintainers in Context.Value is somewhat arbitrary. My personal reasoning is to imagine a perfectly designed system. In this system, there would be no need for introspecting an application, no need for debug logs, and little need for metrics. The system is perfect so maintenance problems don’t exist. Unfortunately, the reality is that we do need to debug systems. Putting this debug information in a Context object is a compromise between the perfect API that would never need maintenance and the realities of wanting to thread debug information across an API. However, I wouldn’t particularly argue with someone that wants to make even debugging information explicit in their API.
我承认在Context.Value中为维护者创建一个异常有点武断。 我个人的推理是想象一个完美设计的系统。 在这个系统中,不需要自检应用程序,不需要调试日志,也不需要度量标准。 该系统非常完美,因此不存在维护问题。 不幸的是,现实是我们确实需要调试系统。 将这个调试信息放在Context对象中是一种永不需要维护的完美API与希望在API中调试信息的现实之间的折中。 但是,我不会特别与某个想要在其API中明确调试信息的人争论。
Try not to use context.Value
You can get into way more trouble than it’s worth trying to use context.Value. I empathize about how easy it is to just add something into context.Value and retrieve it later in some far away abstraction, but the ease of use now is paid for by pain when refactoring later. There is almost never a need to use it and if you do, it makes refactoring your code later very difficult because it becomes unknown (especially by the compiler) what inputs are required for functions. It’s a very contentious addition to Context and can easily get one in more trouble than it’s worth.
你可能会遇到比使用context.Value更值得的麻烦。 我同情将它添加到上下文中是多么容易。在稍后的抽象中对它进行值和检索,但现在的易用性在稍后进行重构时会受到痛苦。 几乎从不需要使用它,如果这样做,它会使得代码的重构变得非常困难,因为它变得未知(尤其是编译器)函数需要什么输入。 这是对Context的一个非常有争议的补充,并且可以轻松获得比其价值更大的麻烦。
from @Jack Lindamood
扩展阅读
- golang.org/pkg/context/
- Go语言实战笔记(二十)| Go Context
- https://medium.com/@cep21/how-to-correctly-use-context-context-in-go-1-7-8f2c0fafdf39
- Golang 并发 与 context标准库
- Go语言经典库使用分析(二)| Gorilla Context
茶歇驿站
一个可以让你停下来看一看,在茶歇之余给你帮助的小站,这里的内容主要是后端技术,个人管理,团队管理,以及其他个人杂想。
