本文是对 Go strconv 包部分源码剖析,我自己收获很多,希望我这篇博文让你也能有收获。
准备工作
基本工作
阅读源码方法
- 选定要阅读的源码包
strconv
- 从上往下顺序阅读,见下图
- 从可导出函数到非导出函数(根据逻辑代码来跳转)
- 有需要时也要读
_test.go
源码清单
1. atob.go
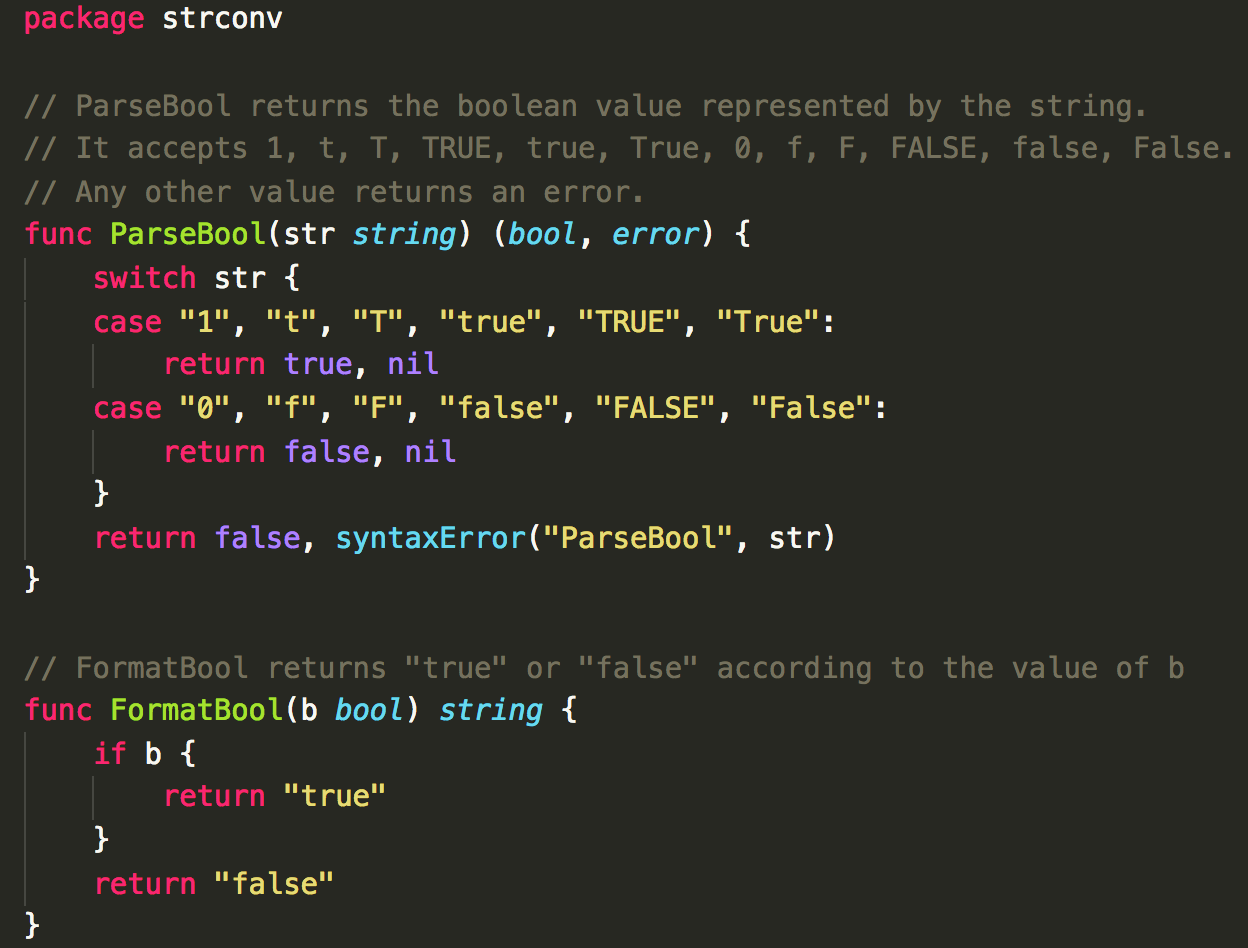
atob.go 的代码真简单。
源码剖析:
ParseBool
使用 switch 来进行判断转换 true/false 。
可转换为 bool 值 true/false的有哪些?
支持:0,1,true,false,t,f,T,F,True,False,TRUE,FALSE,不支持就返回 “invalid syntax”。
FormatBool
使用 if 直接判断,直接 return true/false 。
AppendBool
在指定的字符后添加 bool 值。
2. atof.go
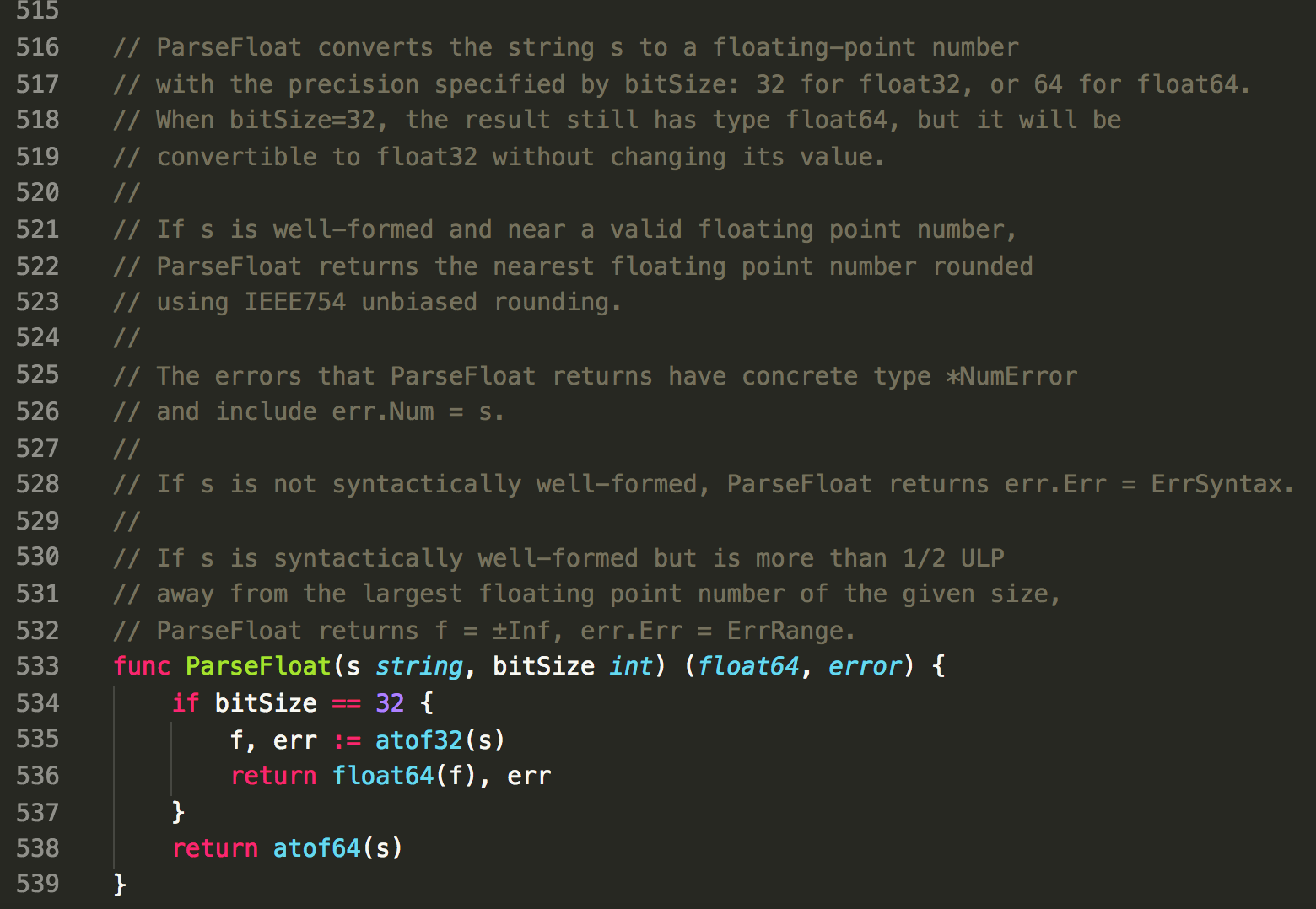
atof.go 一共有 539 行代码,却只有一个可导出函数 func ParseFloat(s string, bitSize int) (float64, error),可想而知,代码逻辑应该不简单。
- ParseFloat
func ParseFloat(s string, bitSize int) (float64, error) 把字符串按照指定的位数转换成 float64 。
32 位单独处理,其他都当做 64 位来处理,32 位和 64 位的处理流程和方法基本上完全一样,只是对应的类型不同而已。
接下来直接来看代码:
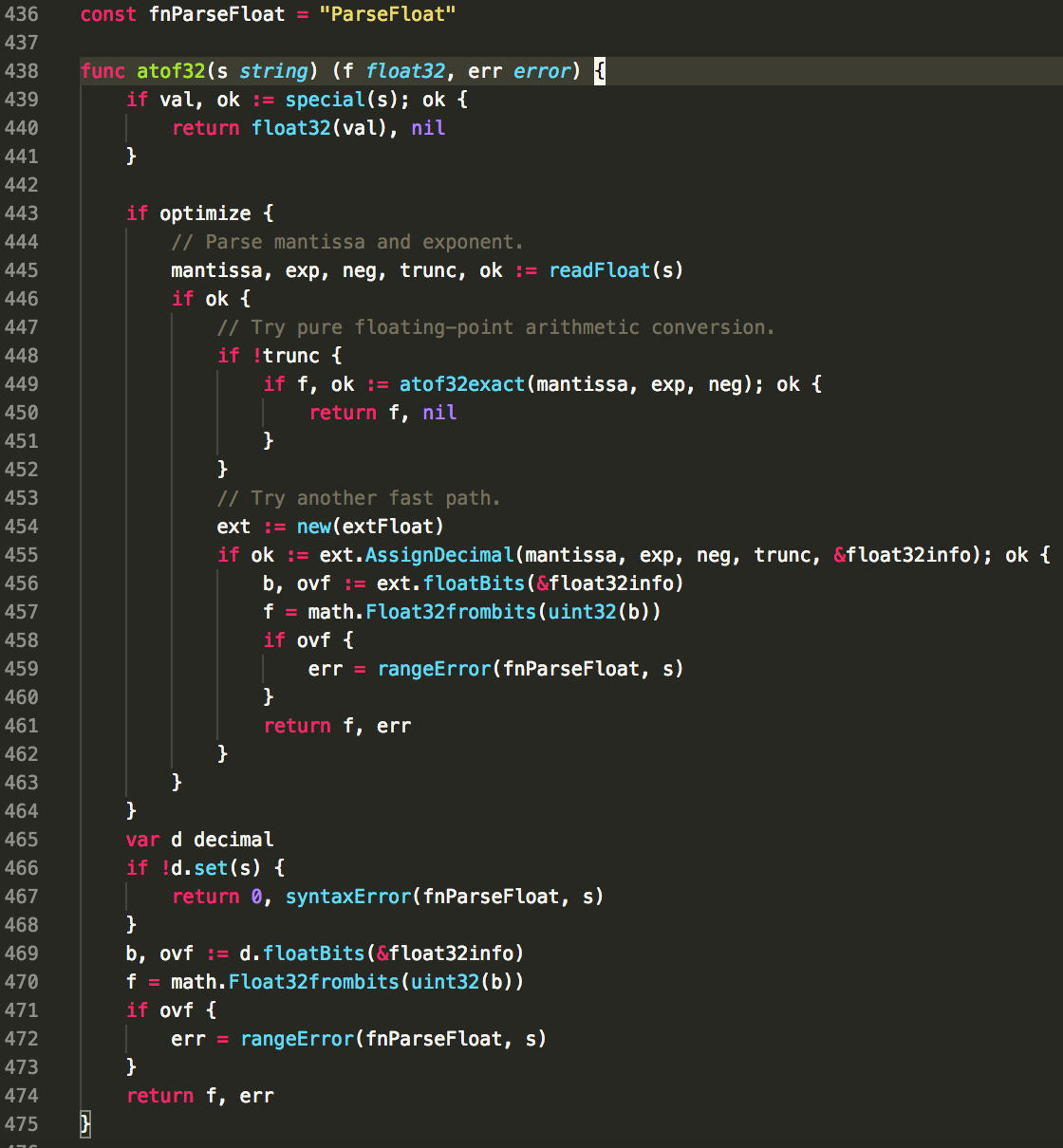
源码剖析:
- 校验给定的字符串是否为特殊值(空,正无穷,负无穷,NaN)
- optimize 用于优化处理科学计数法
- 字符串转换成
decimal 类型
- 由
decimal 类型转换成float64
3. atoi.go
ParseUint
func ParseUint(s string, base int, bitSize int) (uint64, error) 解析字符串为指定进制和位数的正整型。
1.通过 switch 来判断或处理 ParseUint 支持的 base 进制问题(支持从 2 到 36 进制(10+26个字母));
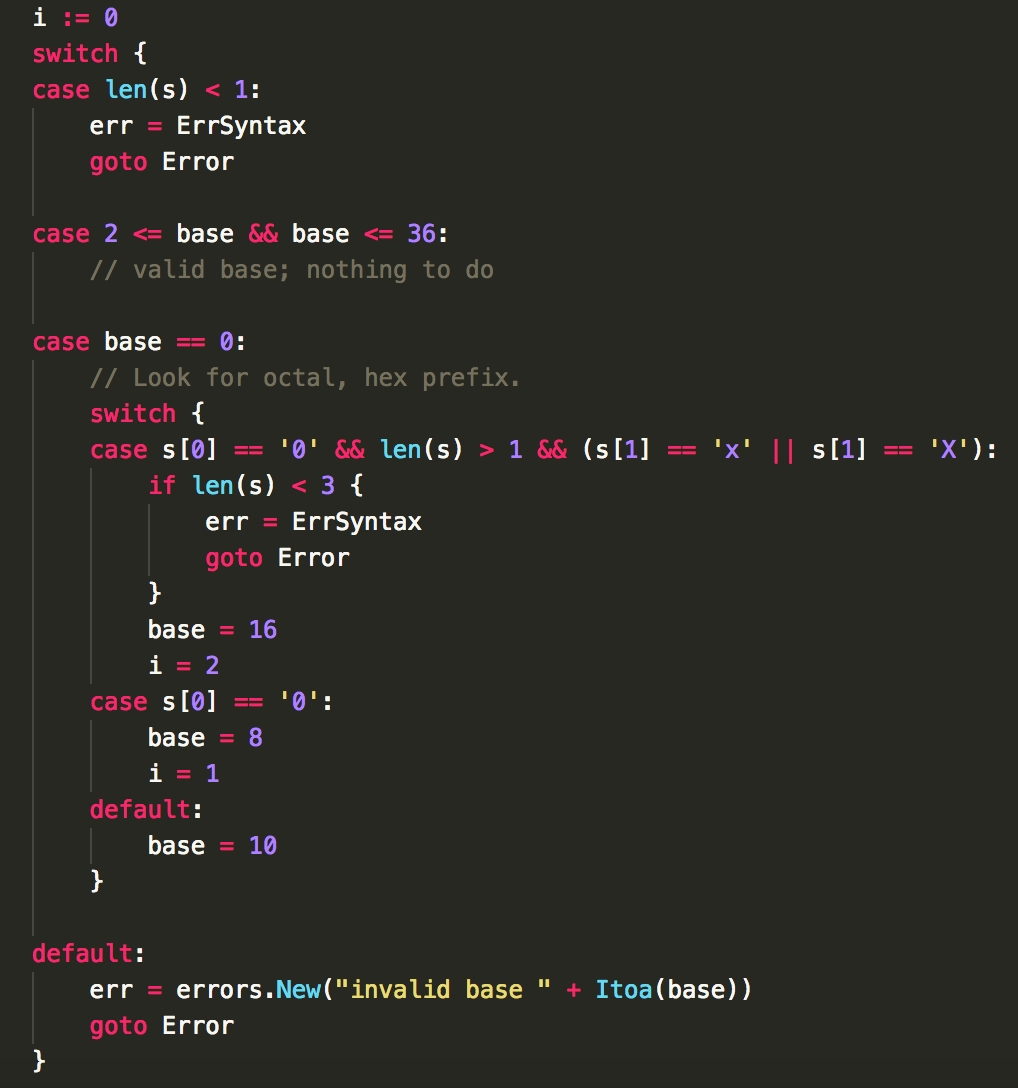
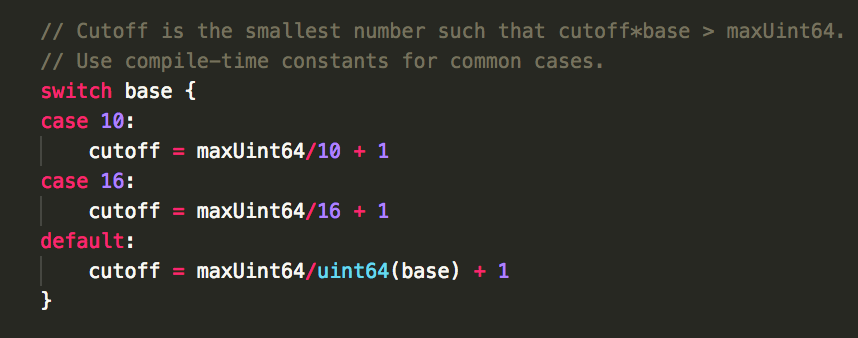
2.cutoff (非常关键,非常重要):cutoff*base > maxUint64 的最小的值(意思就是 cutoff>maxUint64/base ==> cutoff = maxUint64/base+1),通常情况是使用编译时常量(const maxUint64 = (1<<64 - 1))。
3.判断单个字符对应的 byte 值是否溢出。
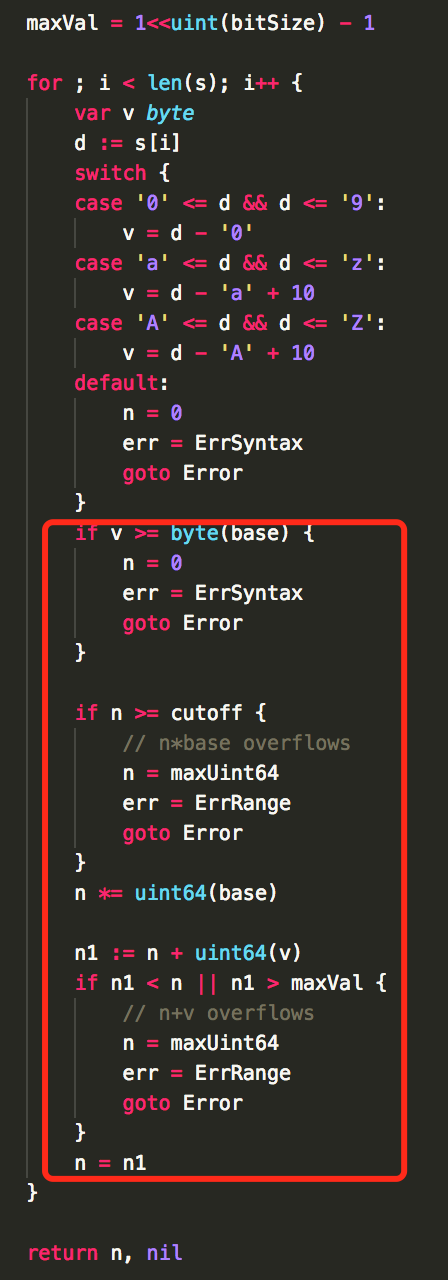
源码剖析:
- for 循环中, n 经过 (
n*=uint64(base))变化后, 如果比隔断的最小值还大的话就会溢出。
- 如果在解析了字符后,
n1 := n + uint64(v),如果 n1 < n 则表示有溢出,因为有可能 n 在上一次循环中已经达到了可以支持的最大值,再+一个数值就会溢出。
- goto 用法,不需要单独定义一个函数,也不需要每个地方都调用一长串 return 内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
|
/*
源码分析:
atoi.go
ParseUint 作用是将一个 string 转成一个 uint ,其中参数 s 是要转成 uint 类型的字符串,base 是进制数[表示字符串中的数字是 base 进制的],bitSize 是 bit 大小[转成 uint 之后,该 uint 在内存中占多少 bit]
*/
package strconv
// ParseUint is like ParseInt but for unsigned numbers.
func ParseUint(s string, base int, bitSize int) (uint64, error) {
var n uint64
var err error
var cutoff, maxVal uint64
// 如果 bitSize 为 0,则会自动根据系统位数来获取 uint 类型的 bit 大小
// 巧妙地运用 uint 获取 bit 大小
// const intSize = 32 << (^uint(0) >> 63)
// const IntSize = intSize
if bitSize == 0 {
bitSize = int(IntSize)
}
// 对传入参数进行一些校验
i := 0
switch {
// 空字符串
case len(s) < 1:
err = ErrSyntax
goto Error
// 进制允许范围
case 2 <= base && base <= 36:
// valid base; nothing to do
// 进制为 0 时,会根据字符串内容自动判断 base,和记录转数字操作时从字符串的第 i 位开始【如 0x122,则 base = 16,i = 2】,如果字符串不是 0 或 (0x|0X) 开头的数字,则默认 base = 10,i = 0
case base == 0:
// Look for octal, hex prefix.
switch {
case s[0] == '0' && len(s) > 1 && (s[1] == 'x' || s[1] == 'X'):
if len(s) < 3 {
err = ErrSyntax
goto Error
}
base = 16
i = 2
case s[0] == '0':
base = 8
i = 1
default:
base = 10
}
default:
err = errors.New("invalid base " + Itoa(base))
goto Error
}
// Cutoff is the smallest number such that cutoff*base > maxUint64.
// Use compile-time constants for common cases.
switch base {
case 10:
cutoff = maxUint64/10 + 1
case 16:
cutoff = maxUint64/16 + 1
default:
cutoff = maxUint64/uint64(base) + 1
}
// 要转成数字所属 unit 类型的最大值
maxVal = 1<<uint(bitSize) - 1
// 从字符串的最左边数字位开始转换数字
for ; i < len(s); i++ {
var v byte
d := s[i]
// 通过 ASCII 码计算,得出字符串中对应索引 i 位置的数字
switch {
case '0' <= d && d <= '9':
v = d - '0'
case 'a' <= d && d <= 'z':
v = d - 'a' + 10
case 'A' <= d && d <= 'Z':
v = d - 'A' + 10
default:
n = 0
err = ErrSyntax
goto Error
}
// 当前数字不能 >= 进制数 base
if v >= byte(base) {
n = 0
err = ErrSyntax
goto Error
}
// 为了防止下面 n *= uint64(base) 溢出 panic 做的安全检查
if n >= cutoff {
// n*base overflows
n = maxUint64
err = ErrRange
goto Error
}
// 上一个数字 * base
n *= uint64(base)
// 当前数字,实际是未进位之前的数字
n1 := n + uint64(v)
// n1 < n 判断进位是否正常
// n1 > maxVal 判断未进位之前的数是否溢出
if n1 < n || n1 > maxVal {
// n+v overflows
n = maxUint64
err = ErrRange
goto Error
}
n = n1
}
return n, nil
Error:
return n, &NumError{"ParseUint", s, err}
}
|
结论:干货
- 阅读源码(特别是 Go 标准包)非常有收获:小技巧和逻辑处理;
- 每一个注释你都必须要认真仔细的去分析;
未完待续…
参考资料
- https://golang.org/pkg/strconv/
茶歇驿站
一个可以让你停下来看一看,在茶歇之余给你帮助的小站。
这里的内容主要是后端技术,个人管理,团队管理,以及其他个人杂想。