本文是我在使用 Pandora 平台各组件的过程中遇到的问题总结,希望可以帮助到大家。
logkit(https://github.com/qiniu/logkit) 非常强大,一定要抽时间阅读分析源码。
首先恭喜一下 logkit 项目上 go trending 榜单了。

前文回顾
在上一篇文章中已经介绍了 logkit 的使用以及问题总结,包括 csv,MySQL 读取,本文是上文的问题补充,涉及到 workflow, logkit, logdb, kibana, grafana 等等。
Grafana
Grafana 都不陌生了,前面几篇文章都有谈及,今天会再对一些问题进行总结。
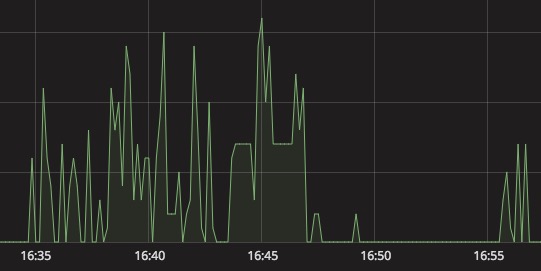
咱们还是先来看看图表吧。
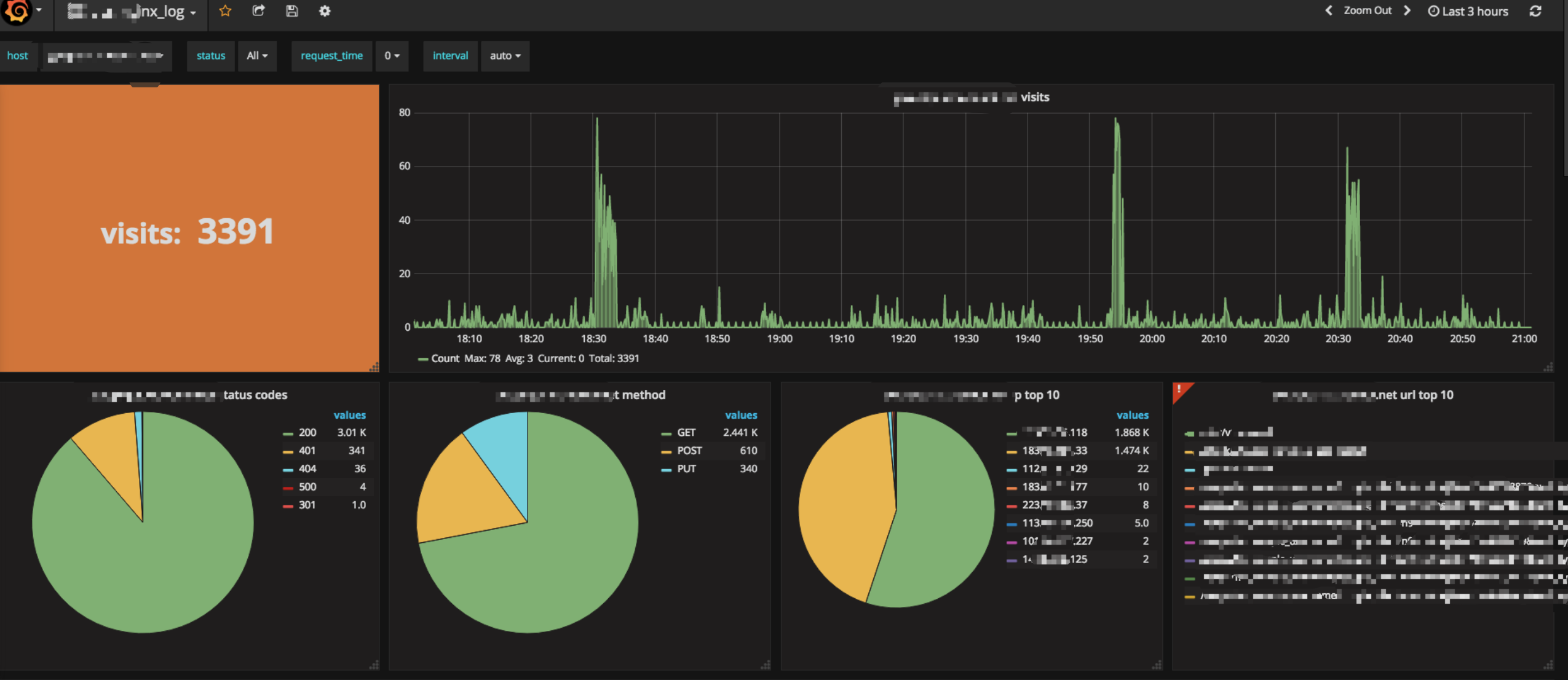
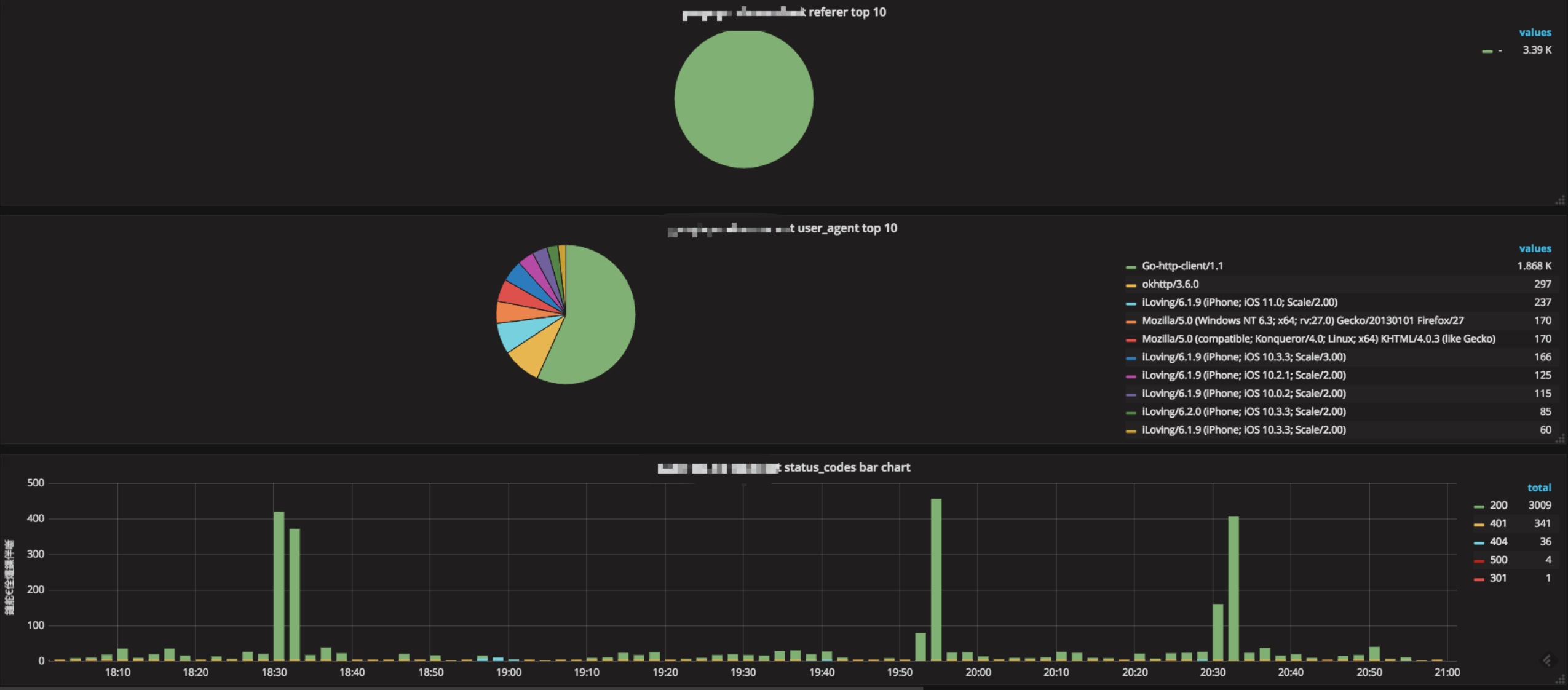
Grafana QA
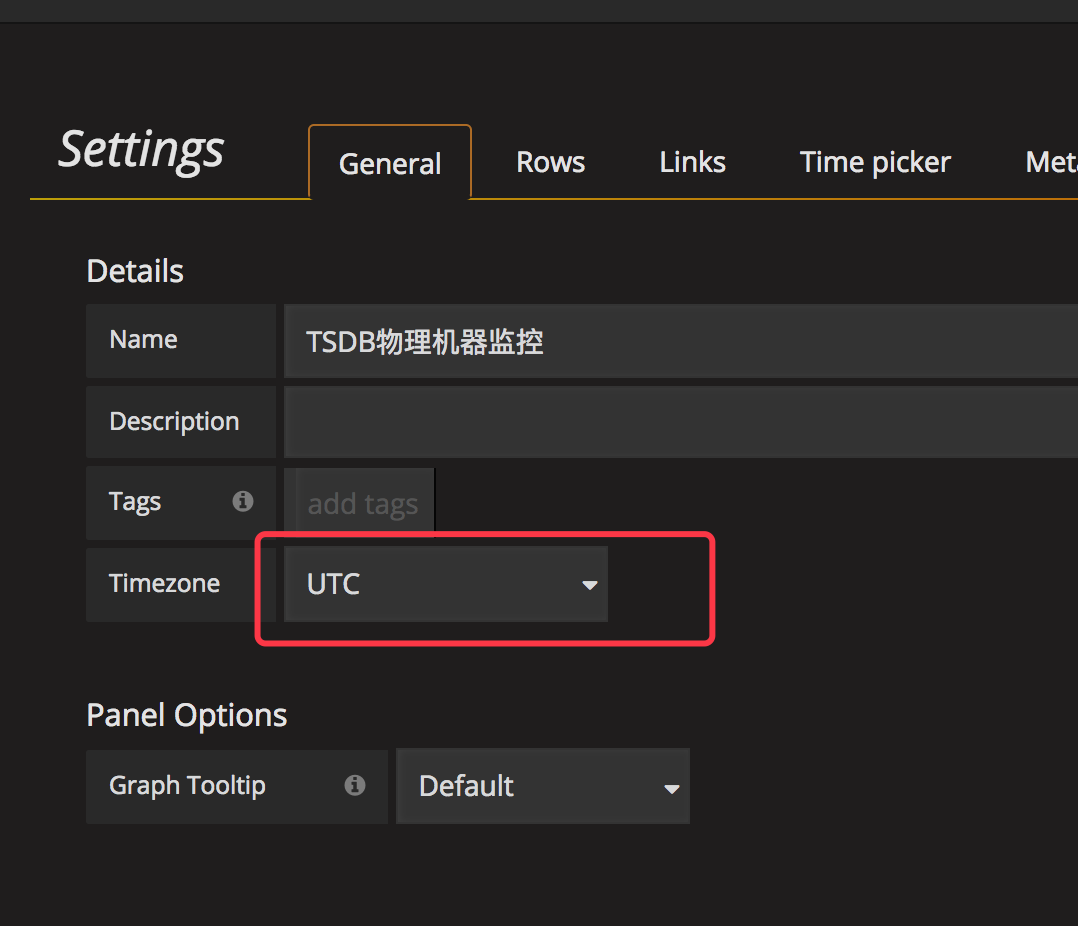
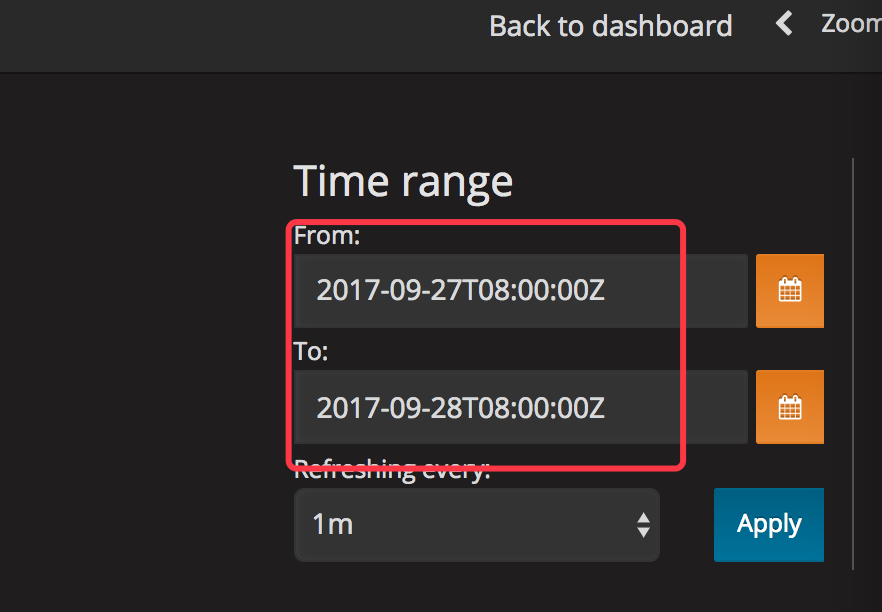
Q0:我选择的是27号,但是数据有26号和27号的呢?(我确认数据源的数据是没问题的。)
出现这个问题是时区的问题,我们可以选择 27号的 8 点到 28 号的 8 点来查看显示结果。
Q1:Dashboard 可以进行时区设置,但是也不行。
出现这个问题是时区的问题,我们可以选择 UTC ,然后再选择时间来查看显示结果。

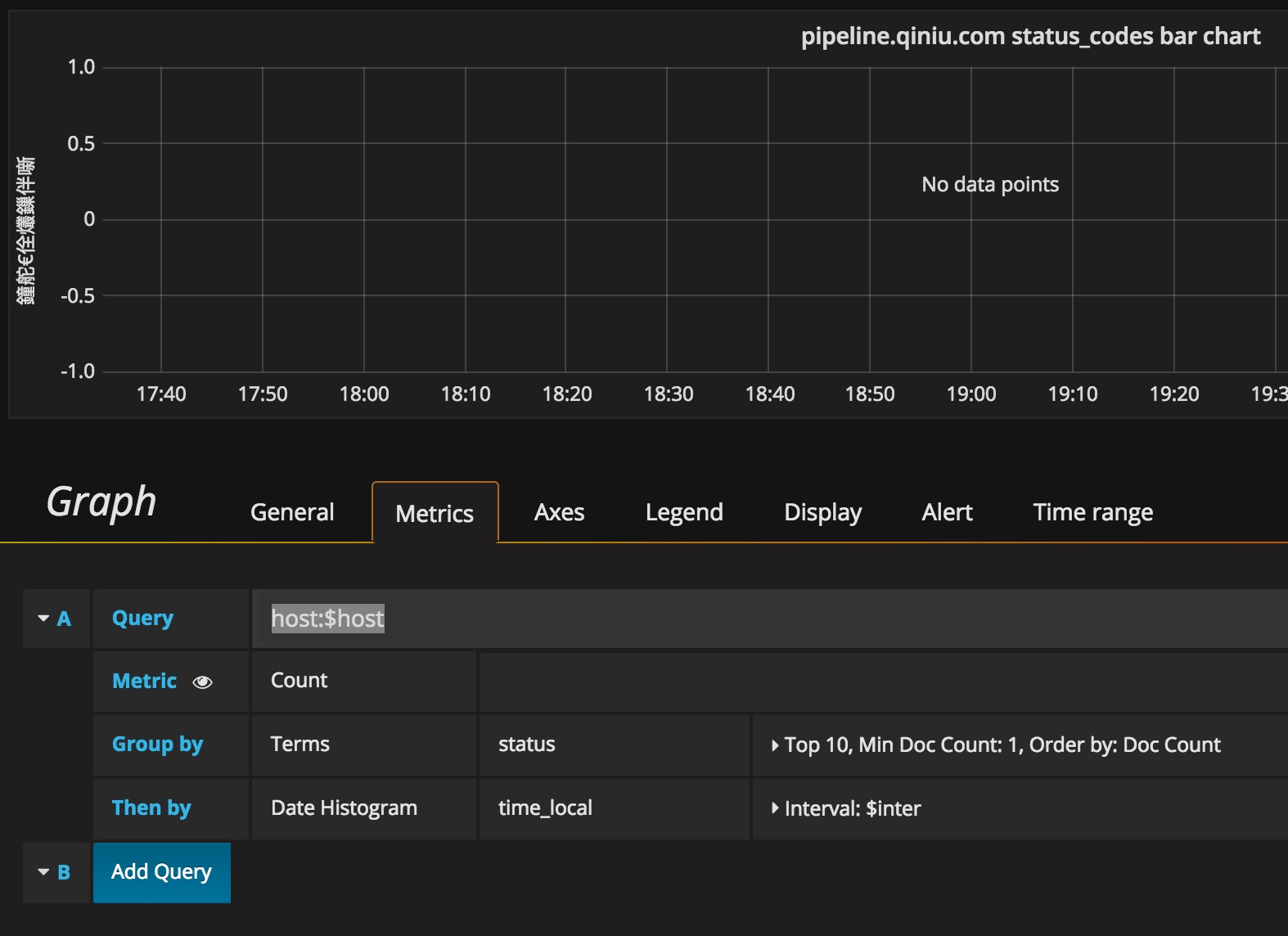
Q2:从工作流导出 nginx_log 为 logdb 后,再使用 Grafana 模板进行展示时,query 带了这个 $host 参数就没有数据?
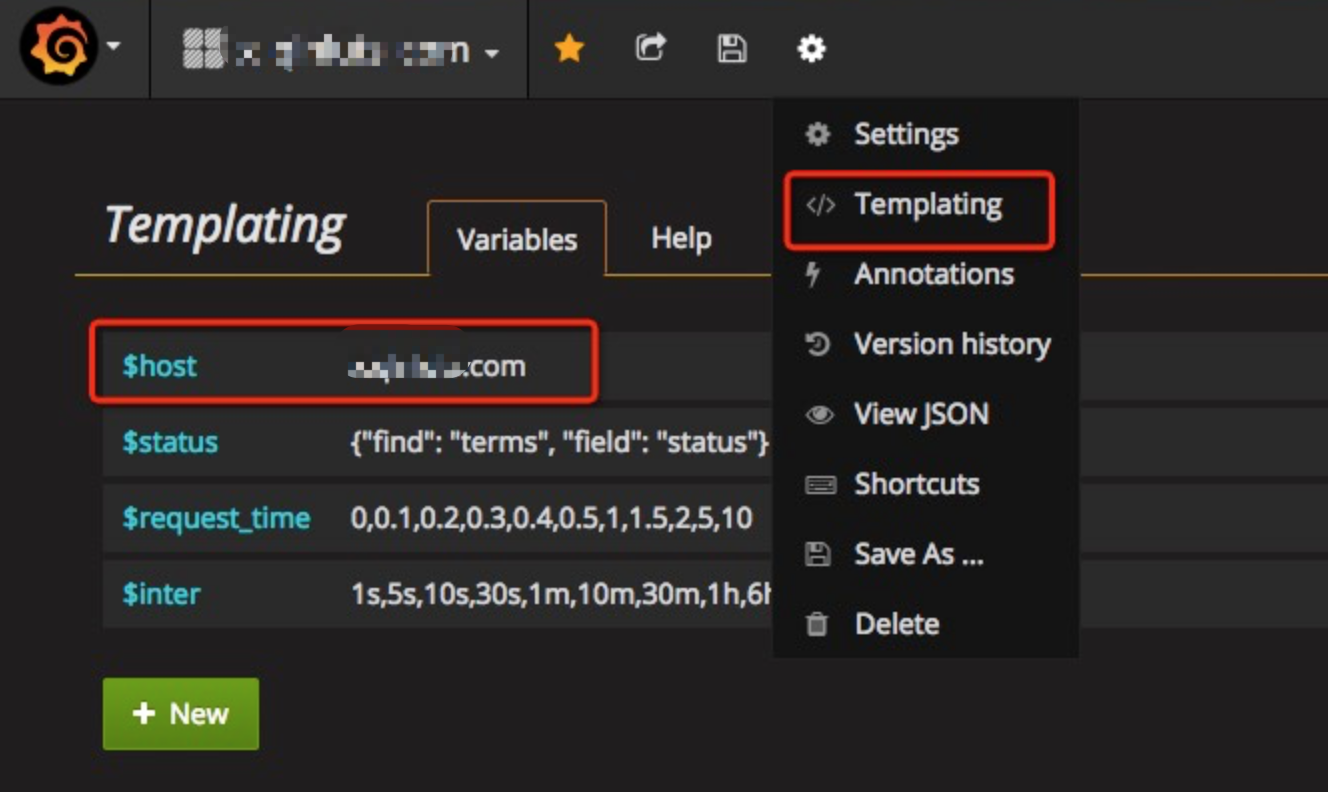
$host这个配置参数,是需要我们事先进行配置的,然后根据你的选择来显示相应的数据。
Q3:Grafana 有哪些酷炫的图表啊?
http://play.grafana.org 这里有很多好玩的模板
Q4:为什么我的 Grafana 上的图表没有形成曲线呢?
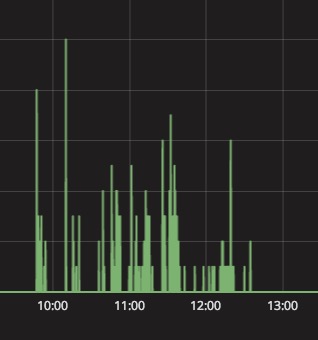
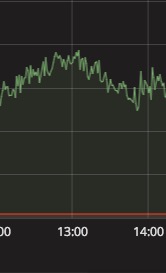
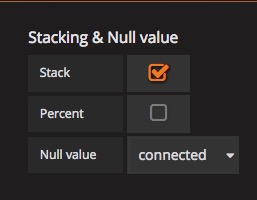
可能你的数据中存在 空 或 0 值,你需要进行以下设置。
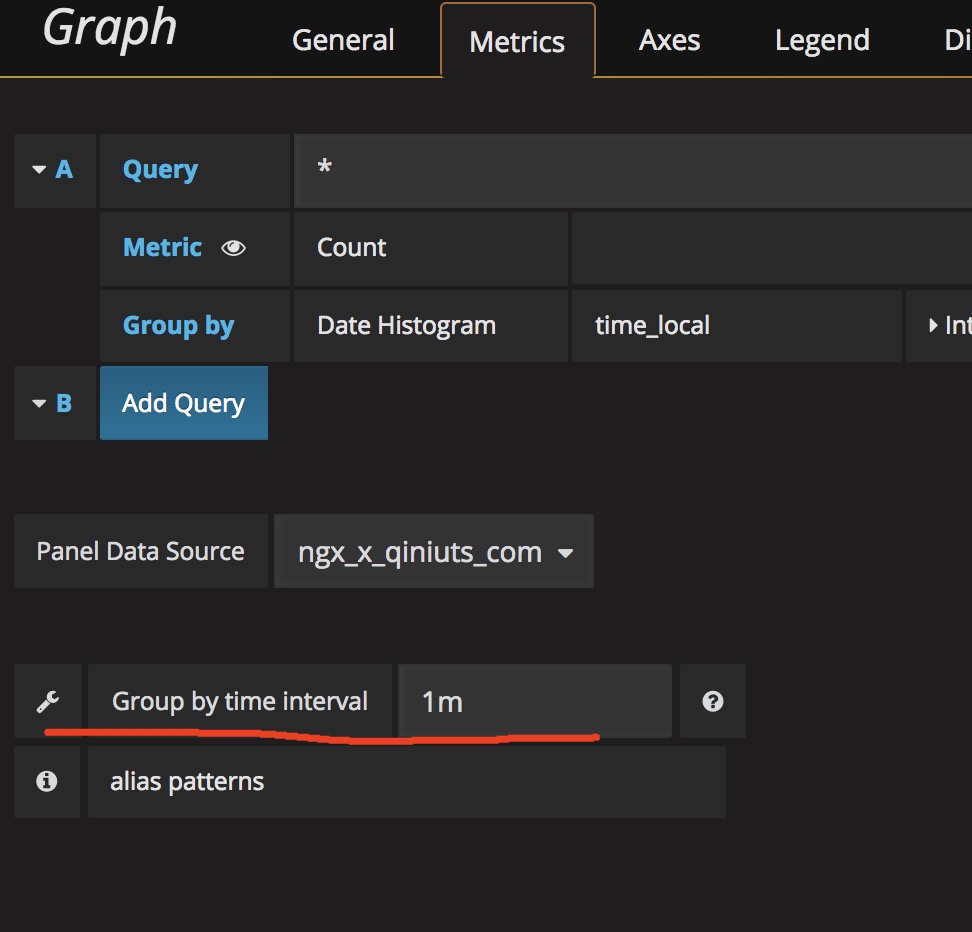
主要原因是因为数据波动很大,然后数据点都比较小,所以你可以把维度调大一点。
logdb 和 Kibana 的 QA
Q0:业务日志以 raw 格式上报,打到 Kibana 里面之后,能够搜索吗?
默认是不分词的,必须是全匹配才可以搜索的到。你也可以更新 logdb 仓库的字段分词方式,然后就可以模糊/分词匹配了。
Q1:为什么出现这个问题?(加入日志文件中的 raw 中包含这个字符串flkx2fx111KPL0000vpg, 在 Kibana 中输入raw:*flkx2fx111,能搜索到结果,但是输入raw:*flkx2fx111KPL0,搜索不到结果。)
查询的时候,查询字符串都会被 lowercase filter 变成小写。当你的 raw 是不分词的方式,是大小写敏感的,所以查询的字符串就不能匹配到你的大写字符串。
你可以修改 logdb 仓库的属性,修改 raw 的分词方式【标准分词器】,可以看下直接搜索了(但是不是马上生效)。
Q2:控制台修改 logdb 的分词什么时候生效?
第二天才生效。
Q3:logdb 怎么分词的?
logdb 会对你的数据进行分词,然后会对词做倒排索引。
Q4:logdb 有哪些分词方式?
分词方式 这里有每一种分词的含义。
Q5:raw 方式上报,默认是怎么分词的?
默认不分词,不分词的话,说明这个字段你必须整体完全匹配才能搜索命中。
Q6:修改仓库的分词之后对之前的数据也生效吗?
不生效,修改只对新数据生效。
logkit 问题
Q0:业务机器(日志分布在 3 台机器上),每一台机器都部署了一个 logkit,我的 confs/xxx.conf 不能一样?
3 台机器,每台机器的 confs 是可以一样的。
Q1:添加的 datasource_tag ,这个怎么查看?
直接在数据中就有,导出到 logdb 时,也会默认导出
datasource_tag所指定的 field 的。
Q2:logkit 上报 pandora_repo_name 改了之后需要重启 logkit 吗?
不需要重启,logkit 配置文件是热加载
Q3:logkit 刚开始指定一个 repo,后面又改了一个会重新创建一个吗?
会重新创建一个。
Q4:两个 repo ,能不能合并为一个?
不能合并。
Q5:部署 logkit 是怎么批量部署到业务机器的?
ansible 等。
Q6:logkit 上报业务日志的,从昨天晚上开始没有上报了。(xxx.log 业务日志被 logrotate 切割了),我采用的mode是:file。
要看你的文件分隔方式是什么,如果是 rotate ,分隔的后缀是时间,那么你得使用 dir 模式,如果是数字的后缀,那么可以使用 file。
如果你的文件是单独写不同文件名的文件,那么你应该使用 dir 模式,如果你是用类似 logrotate 日志切割工具,切出新的文件,那么你应该使用 file 模式,指定具体文件。
更多参考文档:日志收集的模式对应的日志生成场景
*特别注意:*dir 模式,log_path 必须是目录,不能是具体某个文件。
Q7:上报文件是否可以忽略一些文件?
ignore_file_suffix 可选项,针对dir读取模式需要解析的日志文件,可以设置读取的过程中忽略哪些文件后缀名,默认忽略的后缀包括 “.pid”, “.swap”, “.go”, “.conf”, “.tar.gz”, “.tar”, “.zip”,".a”, “.o”, “.so”
Q8:dir 模式会上报目录下所有文件?
除忽略的文件之外的所有文件都上传,按时间顺序。
TSDB 应用场景说明
TSDB 的计费方式其实是为了限制 TSDB 的使用场景,对 20G 及以上的数据要去做复杂的计算,显然不是 TSDB 的使用场景。
TSDB 如果不考虑使用场景,那么就是个多租户版本的 MySQL 。
稍微大一点数据的正确使用姿势是:数据 export 到云存储(kodo)上,然后用离线 workflow 或者 XSpark 分析。
特别是 workflow,运行一次可能就几分钱,最多几毛钱。
强烈建议:在 LogDB 里,重要日志存 7 天,一般日志存 3 天,其余日志不存。 但全量日志都会 export 到云存储(kodo),这样万一需要查的时候,通过 workflow 或者 XSpark 来查。
消息队列分两种: 1、源 repo,就是接受你 logkit 打数据的那个 repo 2、经过 Transform 计算后生成的新的消息队列
实时工作流中, 看看是否有多个 Workflow 。(一般一个 Workflow 中会包含一个源 repo + N 个目的 repo ) repo=消息队列
实时工作流的计算任务要注意,一旦起来,就是一直在运行了。 所以可以确认下哪些计算任务是没用的,那么可以删除掉,以免产生额外费用。
repo ——>计算——>repo
实时计算不仅会产生计算费用,还会产生新的消息队列费用(因为每个计算都会默认生成一个新的消息队列)。
在实时性要求不是很高的情况下,可以考虑选用离线工作流的计算。
七牛 DEM 问题
数字化体验监控(DEM,Digital Experience Monitoring)是多个来源采集的数据集组合起,通过将可视化,分析和机器学习功能方法,来实现可用性和性能监控的方法。通过观察和分析数据集,来优化应用和服务,达到提升终端,人和设备的体验的目的。
Q0:DEM 有文档吗?
Q1:DEM 是怎么收费的?
目前根据 pandora 的用量收费
Q2:DEM 是怎么打点的?
DEM 是通过 SDK 打点的,跟 logkit 的打点是有区别的sdk 打点到 DEM 的 api gate,DEM 的服务端进行合并再打到 Pandora 。
其他
Q0:报表系统怎么开始使用?
https://bi-studio.qiniu.com 使用七牛账号直接登录即可使用。
Q1:其实我这几篇文章的问题QA,在文档中都是有介绍说明的。
参考资料
- https://qiniu.github.io/pandora-docs/
- https://github.com/qiniu/logkit/wiki
- https://qiniu.github.io/pandora-docs/#/quickstart/report
茶歇驿站
一个可以让你停下来看一看,在茶歇之余给你帮助的小站。
这里的内容主要是后端技术,个人管理,团队管理,以及其他个人杂想。