本文是我在使用 logkit 过程中遇到的问题总结,希望可以帮助到大家。
logkit(https://github.com/qiniu/logkit) 非常强大,一定要抽时间阅读分析源码。
前情回顾
在上一篇文章中已经介绍了 logkit 的使用,参考运维日志分析 – Nginx 日志分析搭建案例构建日志检索系统。
再来回看一下效果图吧,😜
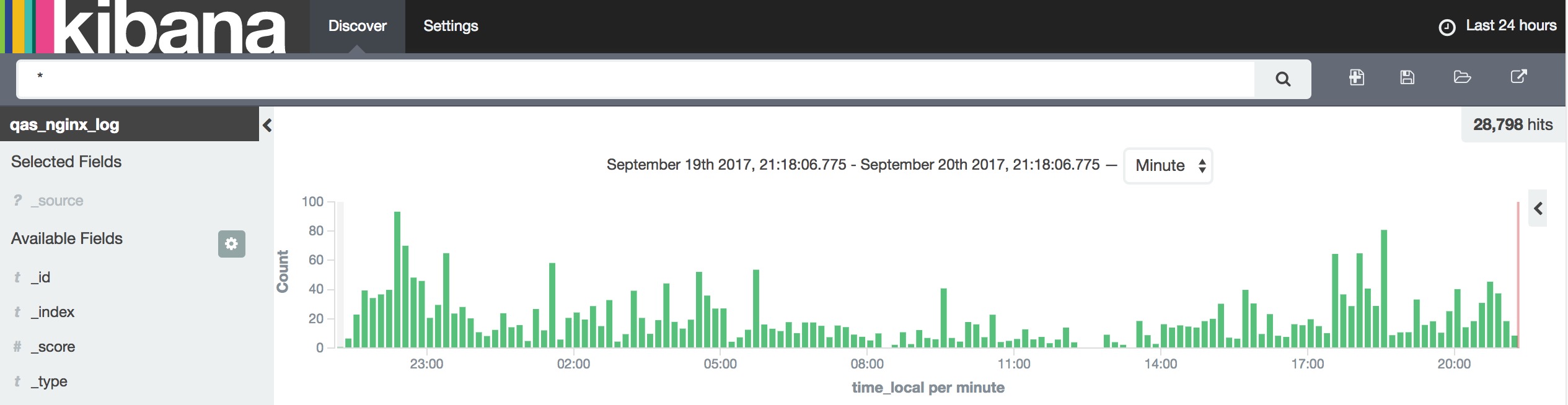
以上图表中的数据均由 logkit 上报所得。
其实 logkit 最核心的就是主配置和 Runner 配置。
Pandora 平台提供的酷炫远不仅于此,你以为 logkit 只能用于日志上报构建日志检索系统吗?那你就错了。
logkit 还可以被用来打点数据
logkit 详解
logkit 介绍
logkit 是七牛 Pandora 开发的一个通用的日志收集工具,可以将不同数据源的数据方便的发送到 Pandora 进行数据分析,除了基本的数据发送功能,logkit 还有容错、并发、监控、删除等功能。
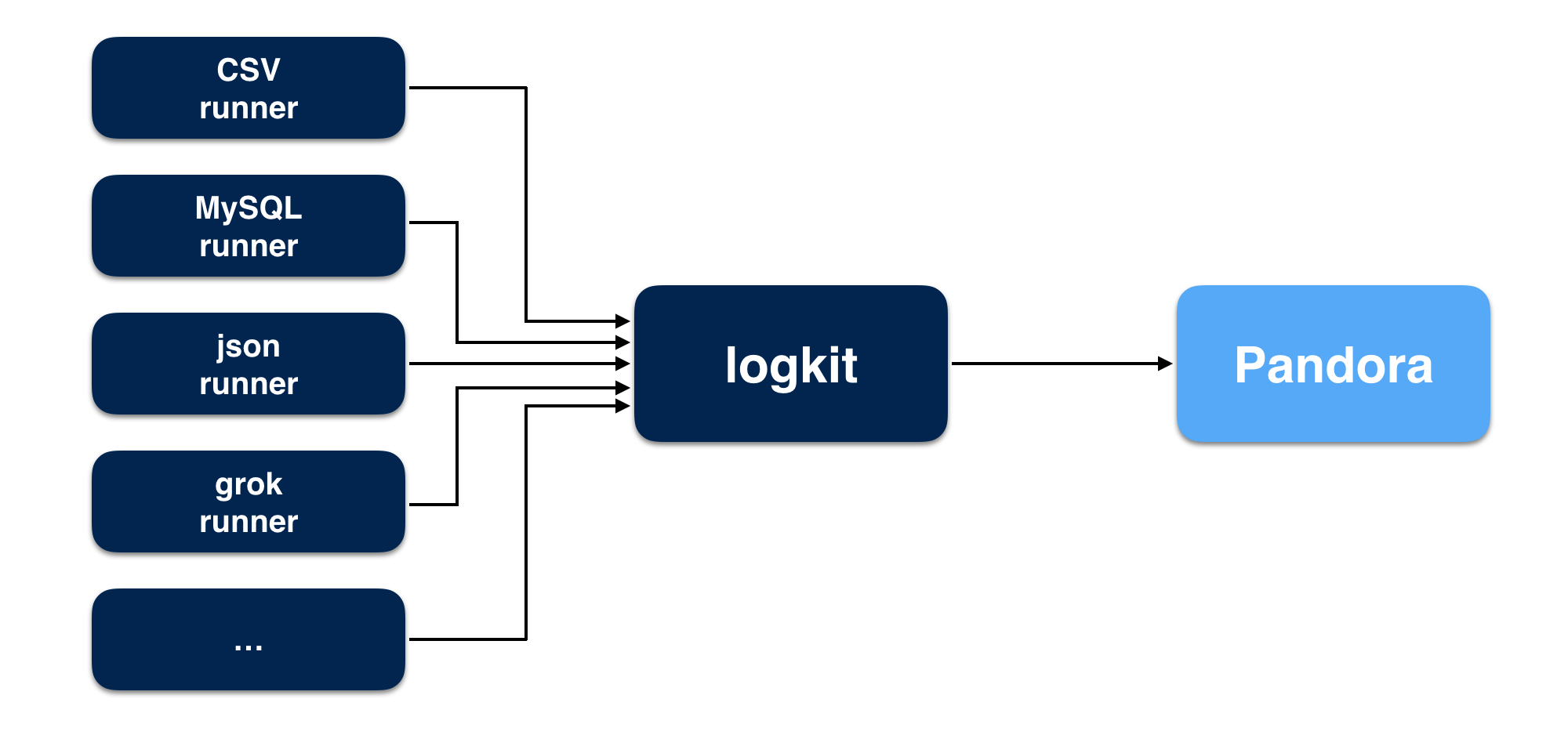
logkit 支持的数据源:
- 文件(包括 csv 格式的文件,kafka-rest 日志文件,nginx 日志文件等,并支持以 grok 的方式解析日志)
- MySQL
- Microsoft SQL Server(MS SQL)
- Elasticsearch
- MongoDB
- Kafka
- Redis
logkit 的安装与使用
logkit 的 README.md 对于安装和使用的介绍非常详尽,我就不再赘述了。
为了把逼格装得高一点,我把图盗过来了,大家先睹为快吧。
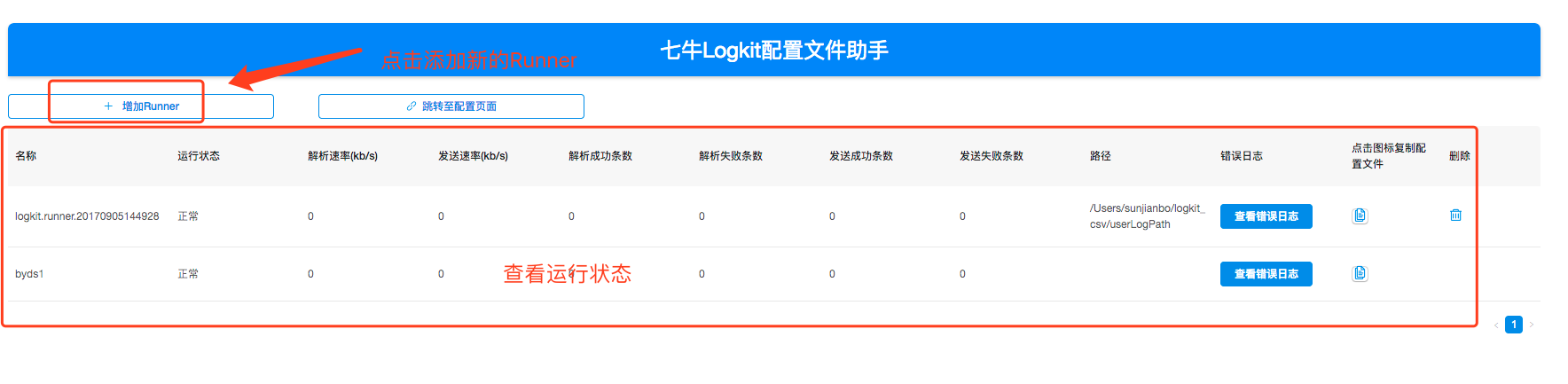
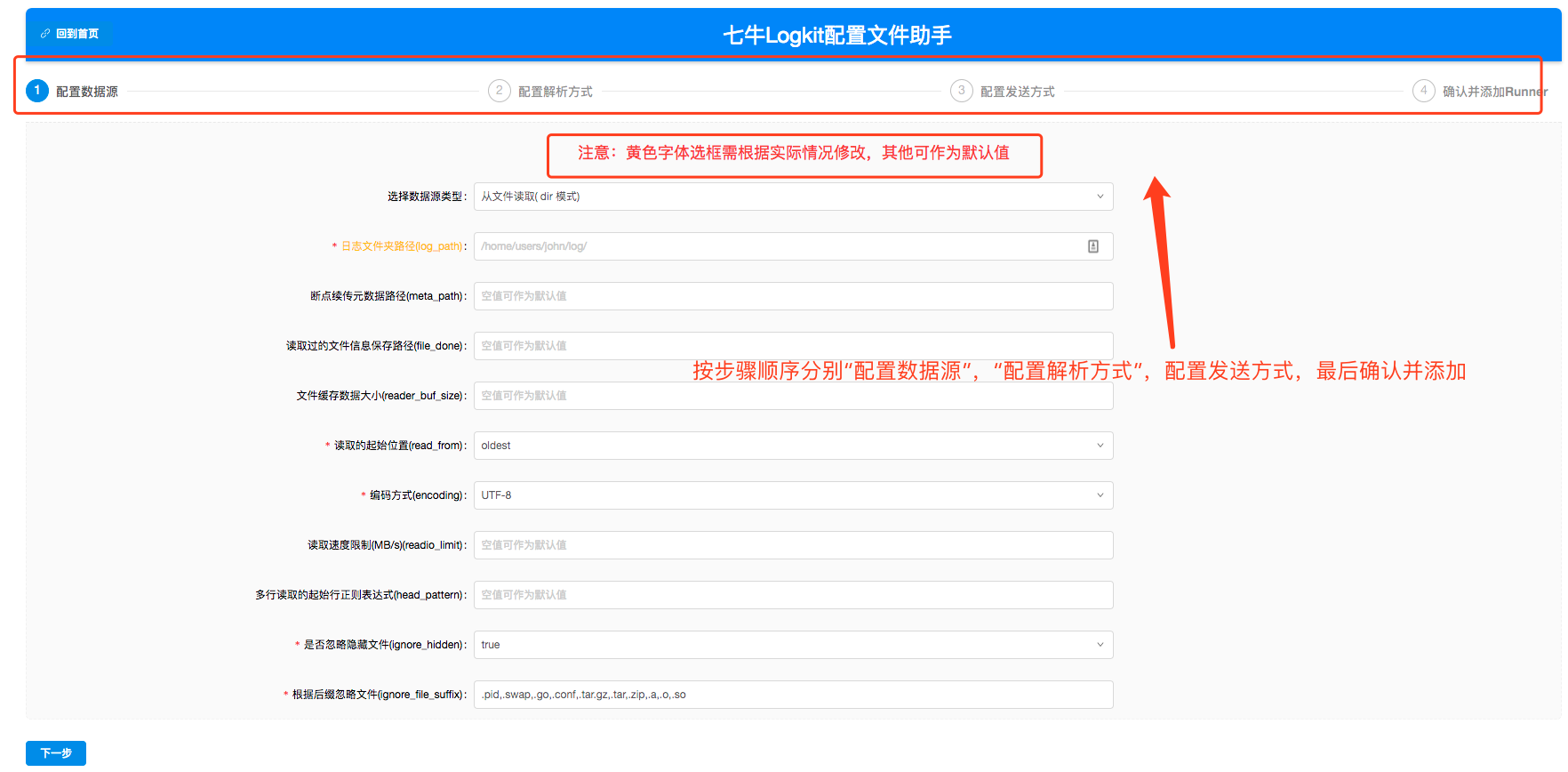
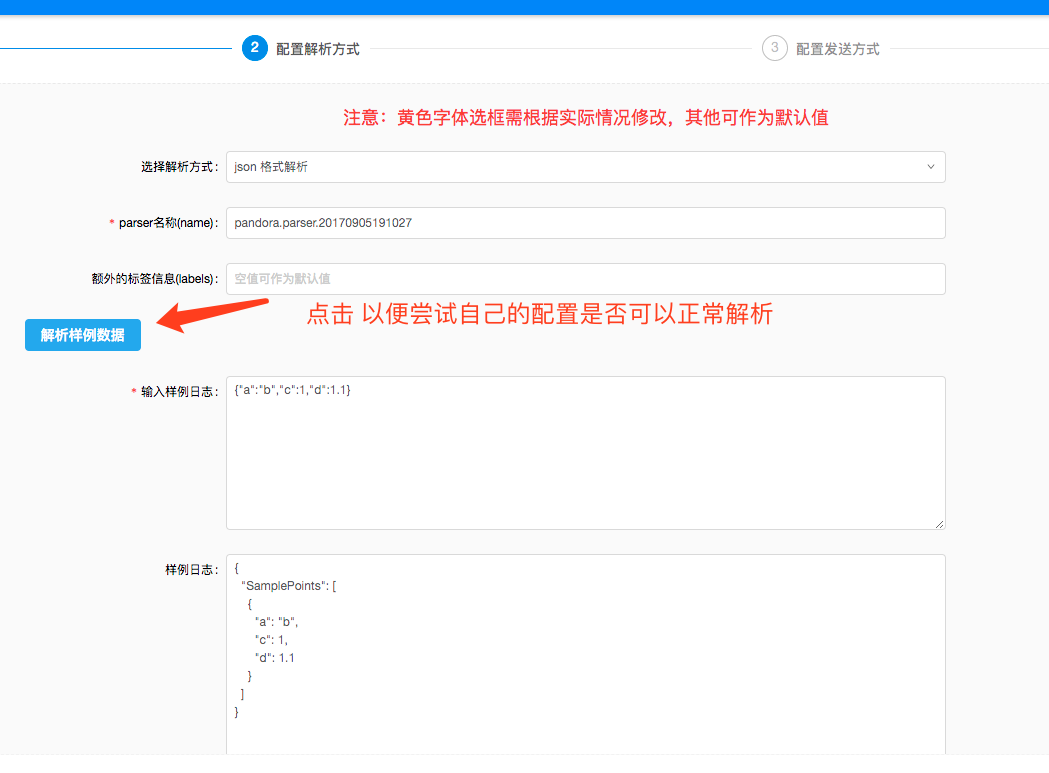
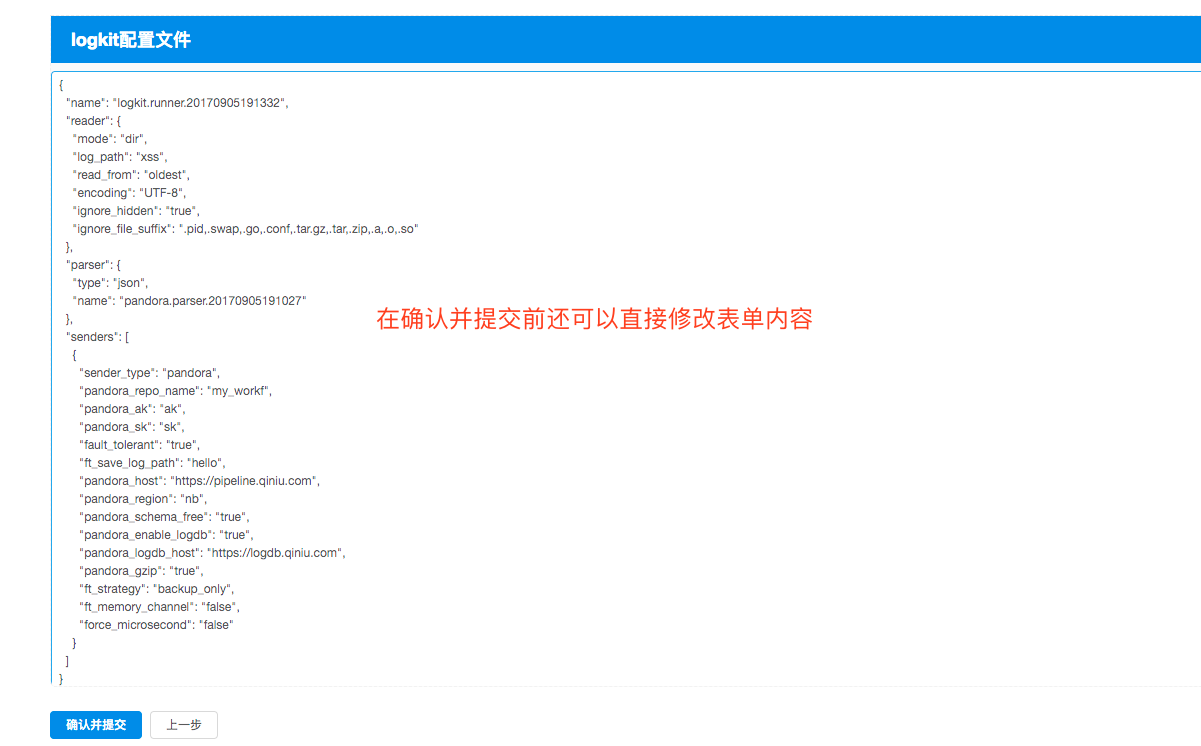
logkit 提供的【logkit 配置文件助手】*,对主配置、Runner 配置方便使用,还有运行情况监控可视化了,真的是业界良心有木有啊。*
打点到工作流
为什么要打点到工作流?
经济实惠(性价比高),方便后续数据转换或存储保留。
其实不同方式的打点,基本上没有太大差别,只需要进行 Runner 配置即可,接下来我就以文件和 MySQL 两种数据源的打点方式来简单介绍吧。
从文件打点到工作流
- 程序不定期的生成文件(程序就不贴了)[可以是csv,也可以是json,只是parser不同而已];
通过配置助手可生成以下配置:
|
|
从 MySQL 打点到工作流
- 向目标数据库插入数据(SQL Insert 语句直接执行);
- 通过配置助手可生成以下配置:
|
|
运行: ./logkit -f logkit.conf ,过段时间即可在工作流上查看到打点数据。
如果你还想看到实时的数据流,那么你将你的数据源做成实时生成数据即可。
QA 环节
Q0: 在 Grafana 监控系统中如何按照特定字段进行排序?
tsdb 默认是按照 time 来进行的,但是你再导出数据时,可以进行指定。但是有一个前提要求是:你使用logkit收集时指定你所需要按照排序的字段为date就可以了。
如果你在导出时找不到你想要选择的排序字段,如下图
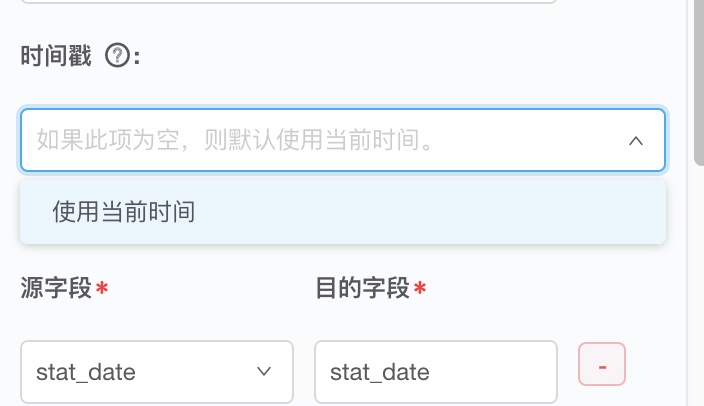
那么你应该检查你的上报字段是不是 date 类型(必须是date类型,或者long类型才能作为时间戳)。
Q1: 怎么给上报的字段指定类型?
修改配置文件中的 senders
pandora_auto_create和pandora_schema,仔细阅读文档(https://github.com/qiniu/logkit/wiki/Pandora-Sender)。
Q2: 如果我想重新打点本地文件或者数据库的数据怎么办?
删除 meta 信息或者直接操作logkit操作界面的重置配置按钮。
Q3: 主配置修改需要重启 logkit 吗?
需要。
Q4: Runner 配置修改需要重启 logkit 吗?
不需要,热加载的。(可阅读源码学习热加载机制的实现)
Q5: Runner 配置修改了批量上报间隔 batch_interval 为 300s ,但是 Grafana 展示数据显示不到 300s 呢?
工作流的导出数据可能存在延时,具体延迟可以在工作流的导出任务中看到明细。

Q6: 工作流导出数据到 TSDB 报错 E7103: Timestamp of points are too far from ?
时间戳可能是离现在太久,比如是一年前的;或者是未来的的时间戳。
Q7: 多久以前的数据无法导出呢?
30天,七牛最大的 retention 是30天。即使你打进了很早的数据,但是因为数据刚打进来就过期了,所以平台对此进行了限制。
Q8:tsdb 时限只有30天,那我该怎么进行报表展示呢?
一般来说实时报表可根据导出到 logdb 或 tsdb 的数据进行 Grafana 统计展示,如果要保留以前的统计数据,则可以通过写入到报表系统来达到目的。 一般来说实时的精度都很高,比如 tsdb 可以精确到纳秒,而以前的数据精度就没必要那么高了,可以处理后写入报表系统。
Q9: logdb 存储时间可以是永久,可以将数据导出到 logdb,然后进行报表展示吗?
可以,但是因为 logdb 存储是收费的,所以不建议这么使用。
Q10: 写数据到文件了,为什么没有上报呢?
确定你是append的方式写文件,而不是新文件,因为上报时会标记上报的位置;其他数据源的方式,也要注意此问题,你要保证你的标记位置没有被重新改变。
其他
- time 字段是时序数据库的关键字,我们在导出时不能用它来进行映射。
关键字还有:“TIME”, “SERVER”, “REPO”, “VIEW”, “TAGKEY”, “ILLEGAL”, “EOF”, “WS”, “IDENT”, “BOUNDPARAM”, “NUMBER”, “INTEGER”, “DURATIONVAL”, “STRING”, “BADSTRING”, “BADESCAPE”, “TRUE”, “FALSE”, “REGEX”, “BADREGEX”, “ADD”, “SUB”, “MUL”, “DIV”, “AND”, “OR”, “EQ”, “NEQ”, “EQREGEX”, “NEQREGEX”, “LT”, “LTE”, “GT”, “GTE”, “LPAREN”, “RPAREN”, “COMMA”, “COLON”, “DOUBLECOLON”, “SEMICOLON”, “DOT”, “ALL”, “ALTER”, “ANY”, “AS”, “ASC”, “BEGIN”, “BY”, “CREATE”, “CONTINUOUS”, “DATABASE”, “DATABASES”, “DEFAULT”, “DELETE”, “DESC”, “DESTINATIONS”, “DIAGNOSTICS”, “DISTINCT”, “DROP”, “DURATION”, “END”, “EVERY”, “EXISTS”, “EXPLAIN”, “FIELD”, “FOR”, “FROM”, “GROUP”, “GROUPS”, “IF”, “IN”, “INF”, “INSERT”, “INTO”, “KEY”, “KEYS”, “KILL”, “LIMIT”, “MEASUREMENT”, “MEASUREMENTS”, “NAME”, “NOT”, “OFFSET”, “ON”, “ORDER”, “PASSWORD”, “POLICY”, “POLICIES”, “PRIVILEGES”, “QUERIES”, “QUERY”, “READ”, “REPLICATION”, “RESAMPLE”, “RETENTION”, “REVOKE”, “SELECT”, “SERIES”, “SET”, “SHOW”, “SHARD”, “SHARDS”, “SLIMIT”, “SOFFSET”, “STATS”, “SUBSCRIPTION”, “SUBSCRIPTIONS”, “TAG”, “TO”, “VALUES”, “WHERE”, “WITH”, “WRITE”
logkit(https://github.com/qiniu/logkit) 非常强大,一定要抽时间分析源码(已经从阅读要升华为分析了)。
题外话
我在 Google 上搜索 logkit 时,看到了下面这张图。
![]()
佐世保最有名气的 LOG KIT 汉堡,既然已经上了图,也不在乎再多上两张。



不喜勿喷。
参考资料
- https://qiniu.github.io/pandora-docs/
- https://github.com/qiniu/logkit/wiki
- http://roodo.iguang.tw/mikiis/archives/40210071.html
茶歇驿站
一个可以让你停下来看一看,在茶歇之余给你帮助的小站。
这里的内容主要是后端技术,个人管理,团队管理,以及其他个人杂想。