本文是我在使用 Pandora 大数据平台的过程中遇到的问题总结,希望可以帮助到大家。

心动不如行动,赶紧开始使用 Pandora 来构建属于你们自己的大数据平台吧。
大数据是什么?
大数据(英语:Big data),又称为巨量资料,指的是传统数据处理应用软件不足以处理它们的大或复杂的数据集的术语。在总数据量相同的情况下,与个别分析独立的小型数据集(Data set)相比,将各个小型数据集合并后进行分析可得出许多额外的信息和数据关系性,可用来察觉商业趋势、判定研究质量、避免疾病扩散、打击犯罪或测定即时交通路况等;这样的用途正是大型数据集盛行的原因。【摘自维基百科】
大数据平台又是什么?
我先给大家看看使用 Pandora 大数据平台构建的一些效果图吧。
Grafana 统计监控:
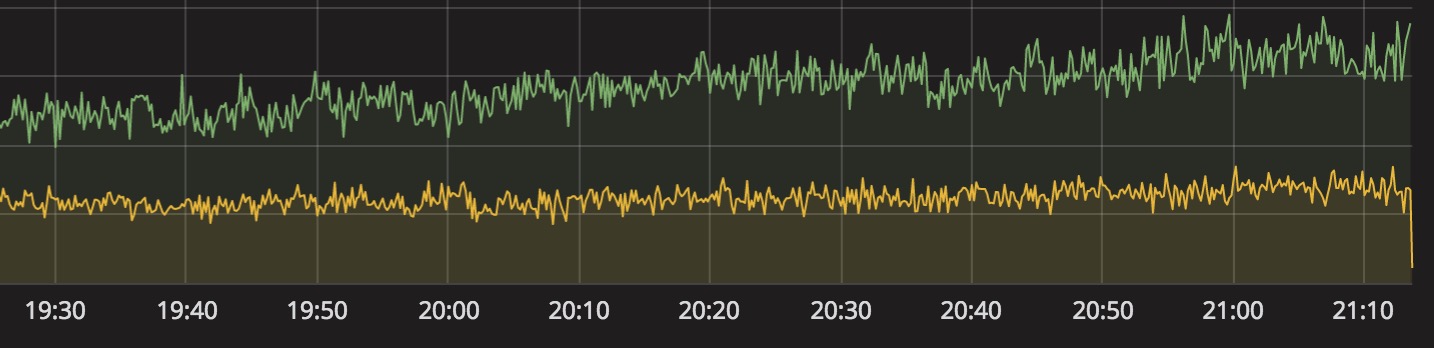
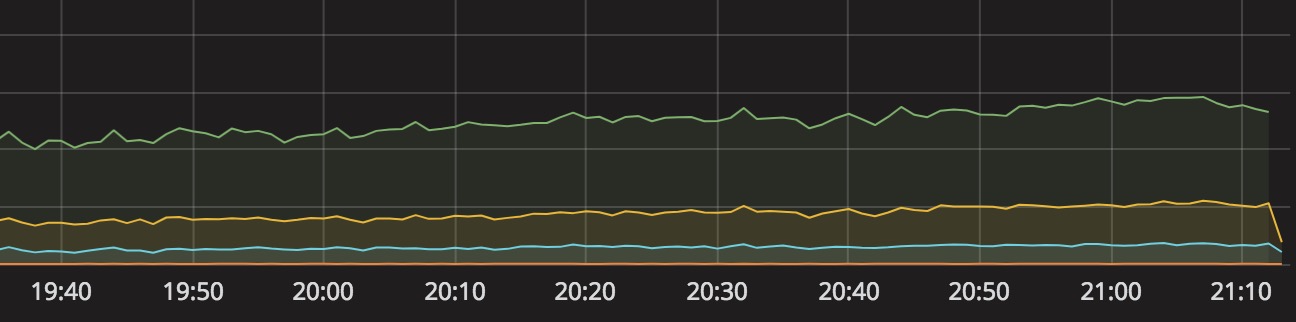

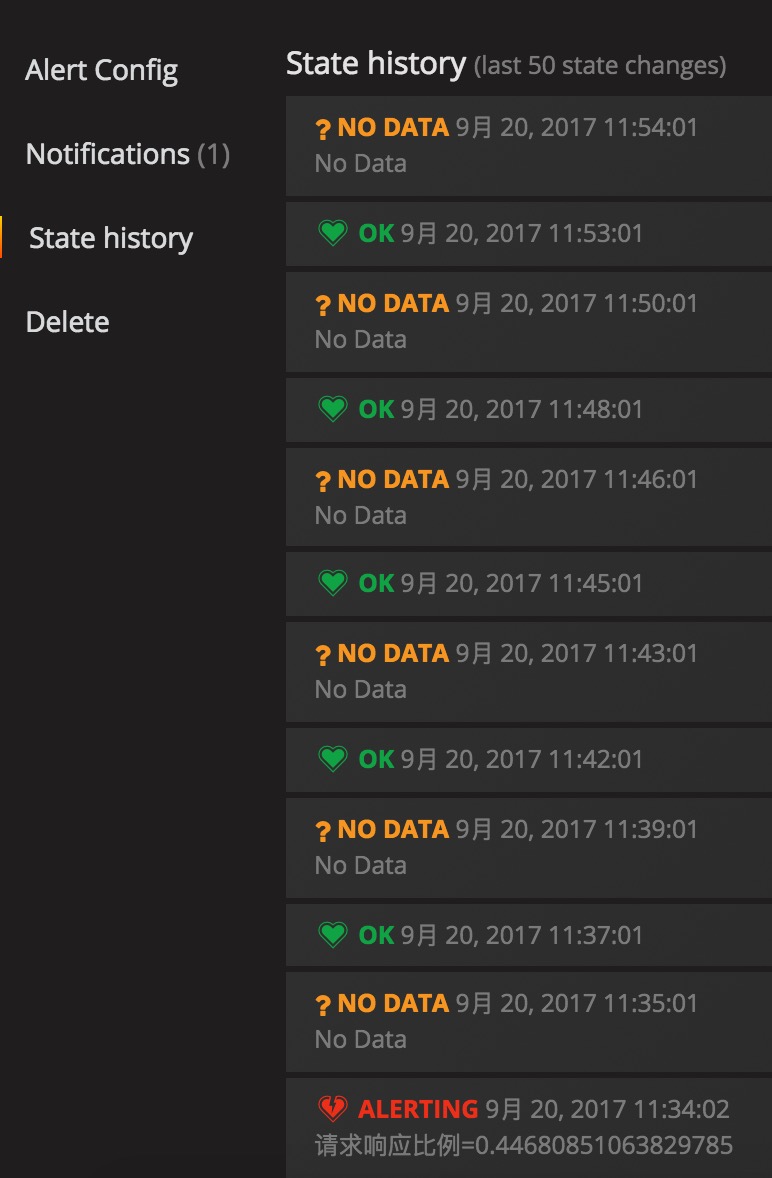
配置告警后的告警历史
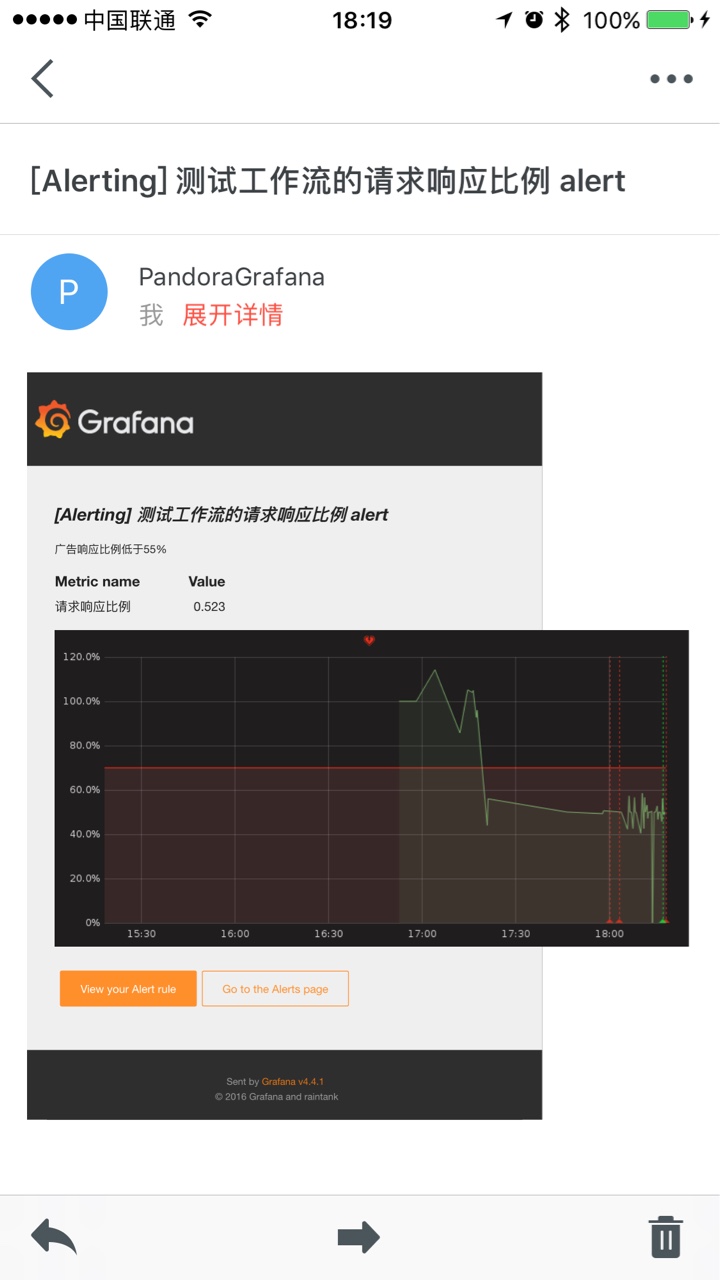
触发警戒值之后还会发邮件的哦(带图的哦)
日志上报后的查询界面
上面这些图表和功能,有没有让你心动呢?
基本介绍
Pandora 潘多拉是一套面向海量数据,以及基础技术人员的,管理大数据传输、计算、存储和分析的大数据平台。
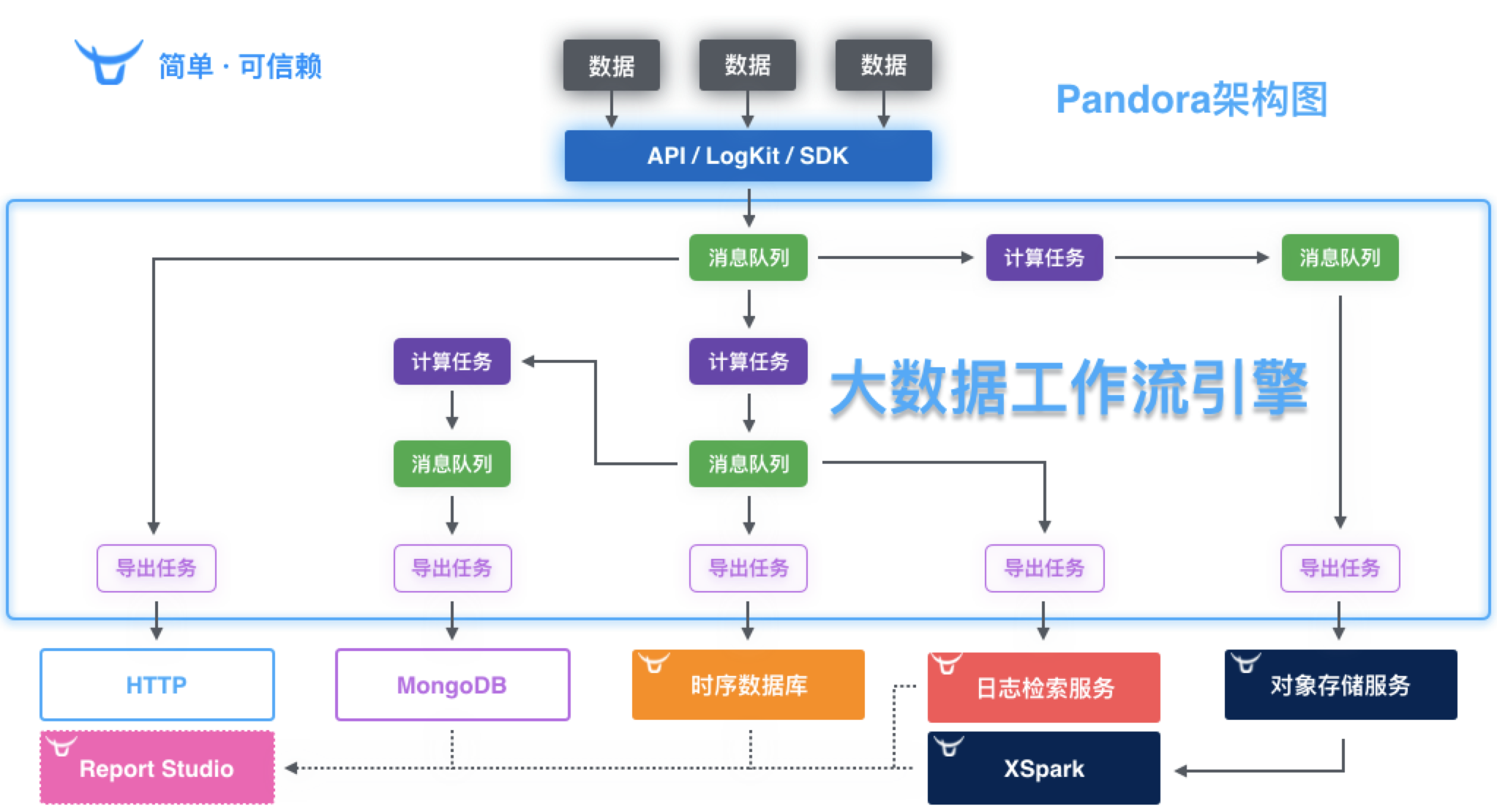
Pandora 共包含五个组件级服务:
| 组件服务 | 概述 |
|---|---|
| 大数据工作流引擎 | 数据接收,(实时/离线)计算和导出(支持多种数据格式:HTTP,日志检索服务,时序数据库,对象存储); |
| 时序数据库 | 时间序列数据库(高速存储,聚合和检索); |
| 日志检索服务 | 海量日志存储和检索; |
| 报表工作室 | 基于数据快速制作动态/静态报表,生成气象观测台; |
| XSpark | 基于 Spark 和容器云,快速进行海量数据分析与可视化; |
如何开始?
目前 Pandora 大数据平台产品处于有限开放、免费试用阶段,你可以联系七牛的销售或客服申请开通试用,也可以发送邮件给 pandora[AT]qiniu.com 注明您的公司名称及联系方式,申请试用。他们在收到申请后一个工作日内为您审核。
- 申请注册七牛账号,登录之后的界面如下:

- 申请 Pandora 大数据平台的相关权限,通过之后登录的界面如下:
从图中,我们可以看出,侧边栏多了大数据工作流引擎、时序数据库、日志检索,容器应用市场,这是 Pandora 包含的 5 个组件的入口。
- 容器应用市场
准备工作
Pandora 大数据平台的基本流程如下:
- 通过(logkit/SDK/API )打数据到工作流(workflow);
- 在 workflow 中,进行数据计算和导出 (可导出到 TSDB/LogDB/HTTP/对象存储);
- 然后在 TSDB/LogDB 中查询数据,或通过 Grafana 进行图表绘制。
其中几个组件服务的基本情况:
- 实时工作流、离线工作流(实时的数据源和消息队列的数据存储时间是2天);
- 时序数据库:创建仓库(类比:数据库)、序列(类比:表)[最大的数据存储时限是30天];
- 日志检索:创建仓库[数据存储时限:最大可设置为永久]
- 容器应用市场:目前官方应用提供有Grafana,Kibana,XSpark;(这 3 个默认是没有开通的,还需要再申请开通),第三方应用暂无;
构建实时和离线工作流
导出数据到对象存储,需要注意:
- 如果我创建导出到对象存储的时候选择最早的话,工作流会追溯所有的数据,一直追到最新的数据(全量数据);
- 如果我创建导出到对象存储的时候选择最新的话,工作流只从此时开始导数据(从此时开始的所有数据);
- 全量数据也只追溯到2天前,因为实时数据源和消息队列的数据存储时间只有2天。
通过(logkit/SDK/API )打数据到工作流(workflow),我们在调用的时候要进行数据包封装,最好不要一次触发一次上报。
新功能:
- 工作流即将支持状态,可以启动和停止;
- 工作流即将增加行为日志;
服务器性能监控
参考文档-服务器性能监控进行构建的。
直接看我搭建好的效果图吧。
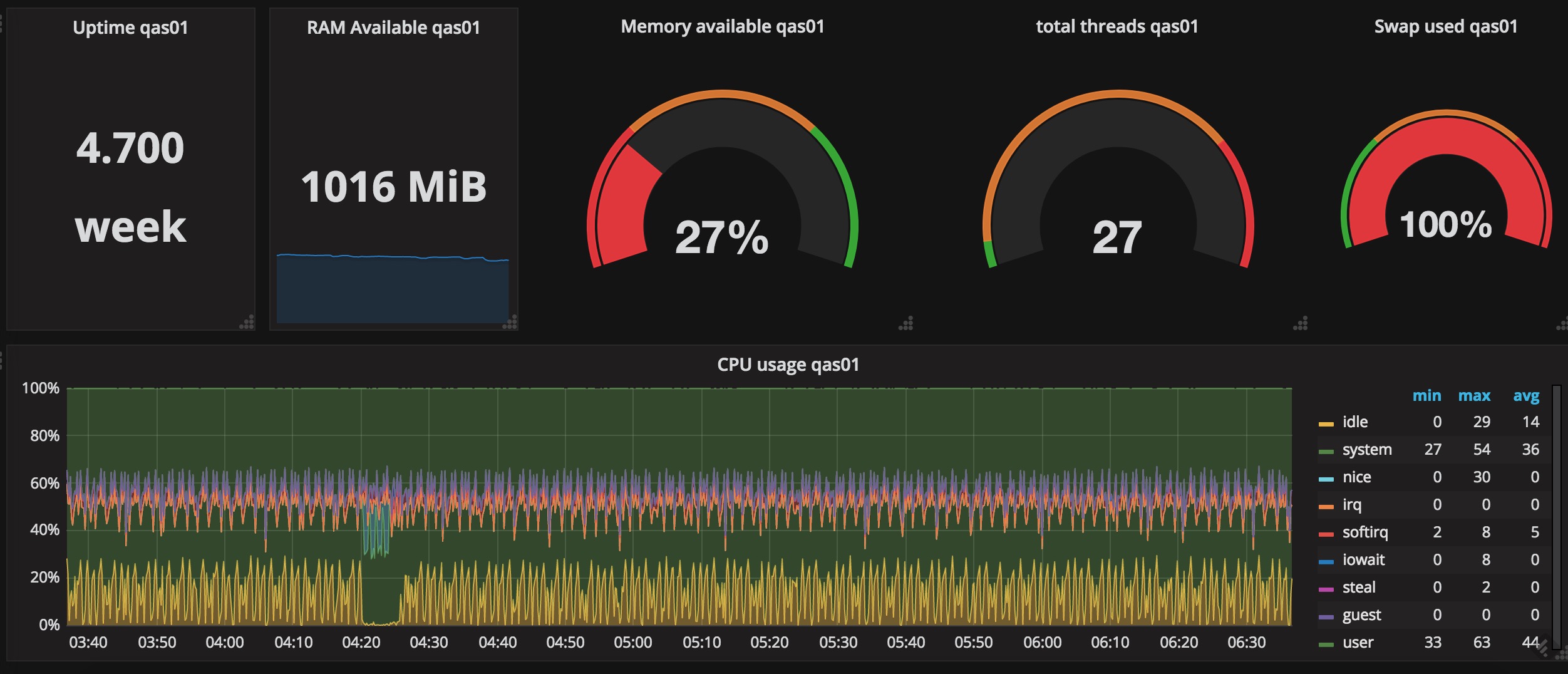
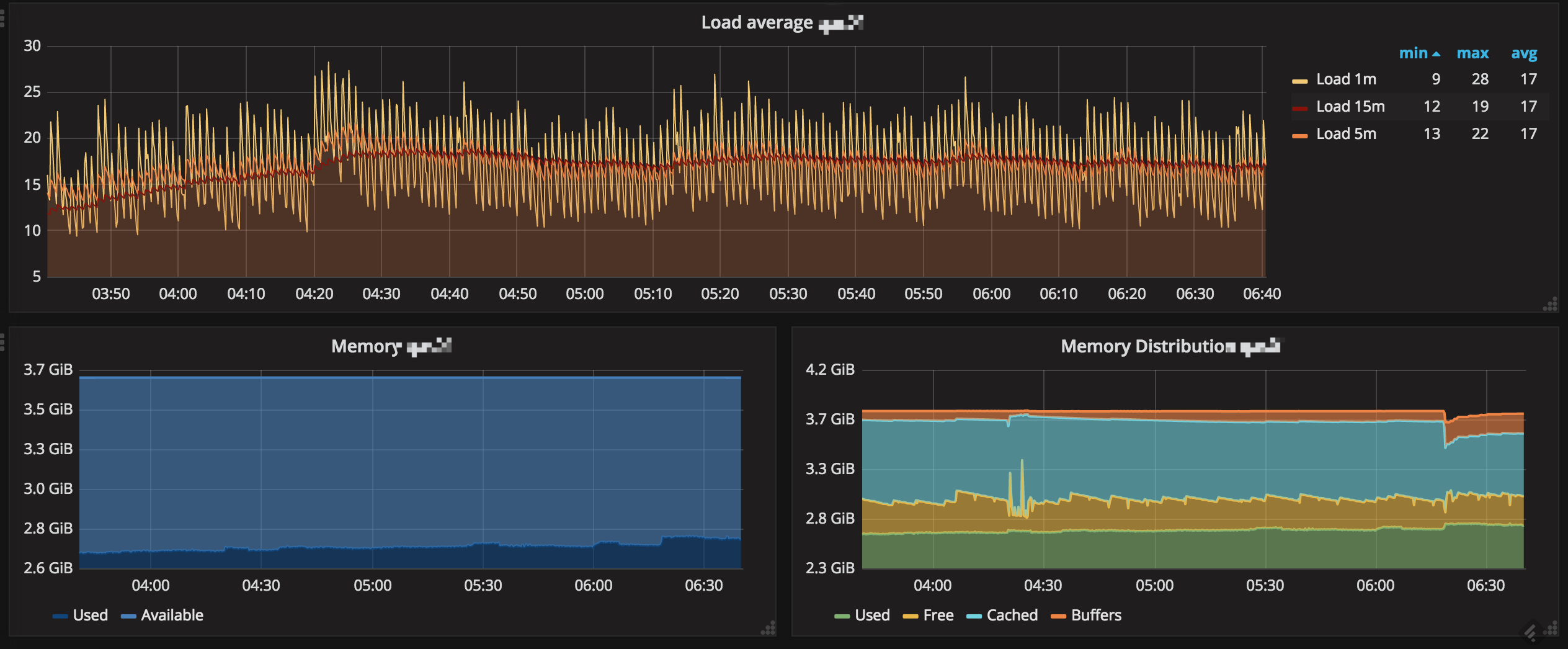
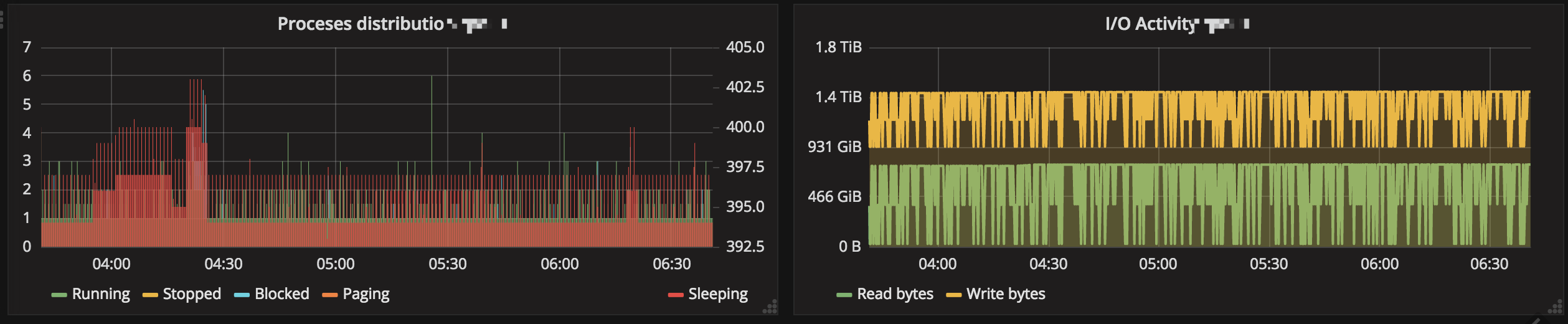
以上数据是使用七牛优化过的 telegraf 上报的。
问题清单:
Q0: telegraf 是什么?
telegraf 是用于收集和上报指标的插件驱动服务器代理(这里使用七牛优化后的版本)。
Q1: 运行 telegraf 报错:create series diskio for repo monitor fail pandora error: StatusCode=404, ErrorMessage=E7100: Repo does not exist!
我们可以提前创建好对应的 Repo ,也可以让程序在第一次使用的时候自动创建资源,如果存在以后就不会创建了。
日志检索,构建容器应用 Kibana
参考文档-运维日志分析 – Nginx 日志分析搭建案例进行构建的。
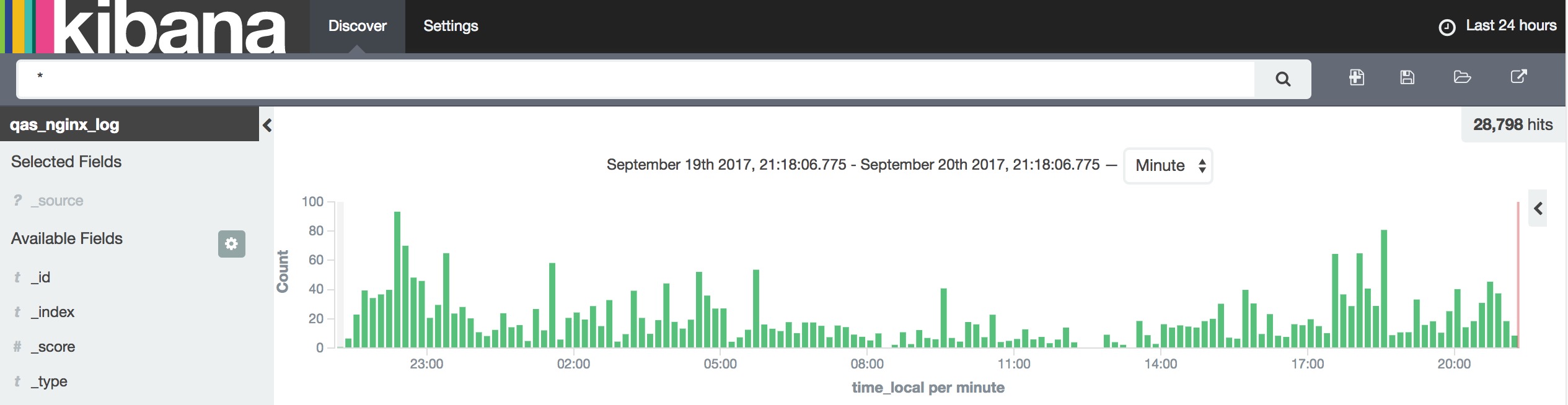
我们先来看看效果图吧,😜
以上图表数据均由 logkit 自动上报。
接下来我将遇到的问题,以 QA 的形式列出来,希望对大家有帮助。
Q0: 七牛的 LogDB+Kibana 和自建的 ElasticSearch+Kibana 相比有什么优势?
- 减少运维成本
- 资源开销更少
- 自建的 ElasticSearch 是单机版的(当然也可以搭建集群),而七牛的 LogDB 是可以水平扩容的;
- 七牛的日志数据库 LogDB 还可以和我们的 workflow 结合,做各种各样的数据转换等功能;
- 还有功能强大的 logkit ;
- 可以直接使用容器应用提供的 Kibana;
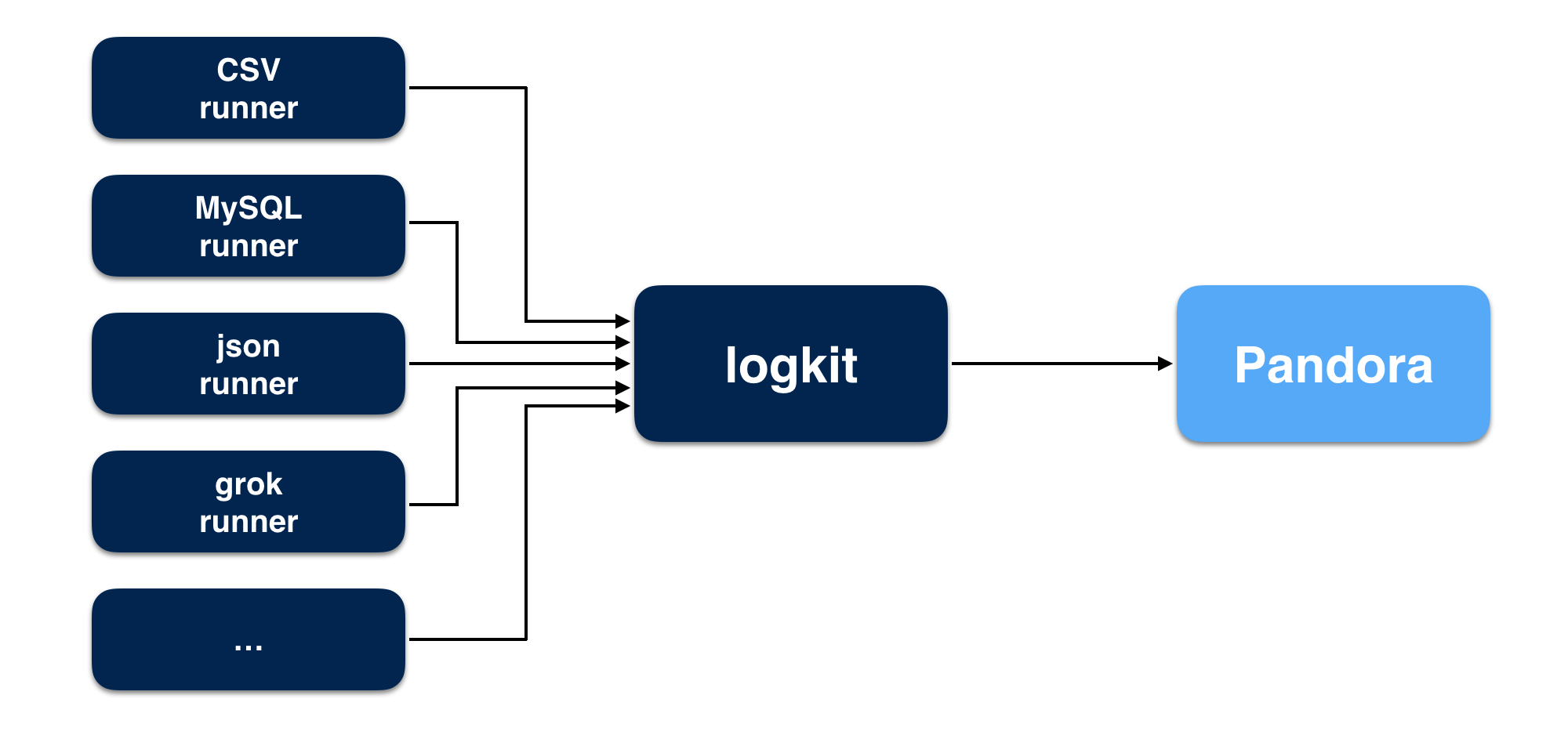
Q1: logkit 是什么?
logkit 是七牛 Pandora 开发的一个通用的日志收集工具,可以将不同数据源的数据方便的发送到 Pandora进行数据分析,除了基本的数据发送功能,logkit 还有容错、并发、监控、删除等功能。
支持的数据源:文件(包括csv格式的文件,kafka-rest日志文件,nginx日志文件等,并支持以grok的方式解析日志)
- MySQL
- Microsoft SQL Server(MS SQL)
- Elasticsearch
- MongoDB
- Kafka
- Redis
Q2: logkit 日志多久上报一次?
Q3: [ERROR][github.com/qiniu/logkit/mgr] runner.go:389: Runner[nginx_runner] parser nginx_parser error : NginxParser fail to parse log
Nginx log format 不匹配导致(更多信息参考nginx-parser,grok-parser)。
Q4: 七牛的 CDN 日志有延时吗?
日志延迟 8 小时,不能做实时监控,只能用离线工作流来做。
Q5: logkit 上报是什么规则?
Q6: 一次请求最大支持多少?
配置文件中可以配置,最大支持 2 MB,尽量将文件合并后上传,减少调用次数,查看Runner之数据采集配置。
Q7: 上报到日志检索服务后怎么查看日志来源?
logkit 有一个可支持配置的日志来源的选项
datasource_tag,更多请看文档
Q8: 搜索结果只有最近几天的数据?
需要配置参数
retention,创建之后默认保留 3 天。
logkit(https://github.com/qiniu/logkit) 非常强大,一定要抽时间阅读源码。
时序数据库,构建容器应用 Grafana
时序数据库是什么?
时间序列的数据库。 业内比较著名的是 InfluxDB 。它是一个由 InfluxData 开发的开源时序型数据库。它由Go写成,着力于高性能地查询与存储时序型数据。InfluxDB 被广泛应用于存储系统的监控数据,IoT 行业的实时数据等场景。 本文则是 TSDB。
步骤很简单:
SDK创建仓库,然后再创建序列,再之后往序列上报数据。
问题(感谢我的小伙伴整理了这么多的问题,希望能对你使用有帮助):
Q0: 你们的时序数据库 TSDB+Grafana 和自建的 InfluxDB+Grafana 相比有什么优势?
- 减少运维成本
- 资源开销更少
- 自建的 InfluxDB 是单机版的,而七牛的 TSDB 是可以水平扩容的,不需要我们干预和关心;
- 七牛的时序数据库 TSDB 还可以和他们的工作流(workflow) 结合,做各种各样的数据转换等功能;
- 可以直接使用容器应用提供的 Grafana ;
Q1: 通过 API 创建仓库时出现 region 错误提示。
TSDB 目前只支持华东区域资源服务器,代号为 nb ,需要指定。
Q2: 创建仓库、序列、数据查询过程中出现 bad token 提示。
鉴权不通过,token 过期,检查 ak/sk 以及 token 。
Q3: 创建过工程中出现ak/sk错误。
- ak/sk 错误;
- 账号并没有添加 pandora 应用。
Q4: 插入数据时提示数据类型错误。
通过 API 请求插入数据时,需要注意类型对应的问题,在请求封装时很有可能会因为 map[][]而忽略这个问题。
Q5: 使用 distinct 去重查询时,并且做 count 计算,数量不符。
需要注意空字段的情况,字段为空时也占用一个量。
Q6: 使用 select tag 查询时出现错误
- 首先需要检查字段是否错误。
- 在 TSDB 中,time 是一个默认的 tag ,在序列中也会自建 tag ,需要注意 tag 并不能作为查询主体,tag 只能作为分组以及查询条件。
Q7: TSDB 中 limit 与 offset 的使用。
limit 使用时与 MySQL 一致,需要注意的是空数据的存在。
Q8: group by 与 order by
group by 只能够对 timestamp 以及 tag 使用,order by 可以用来对 timestamp 使用,做时间聚合。
Q9: TSDB 时间类型
RFC3339 YYYY-MM-DDTHH:MM:SS.nnnnnnnnnZ 使用时间作为查询条件时,可以采用如下运算符:
= 等于
<> 不等于
!= 不等于
> 大于
>= 大于等于
< 小于
<= 小于等于
使用 TSDB 的 SDK 进行数据查询时,可使用
time>'2017-09-18'的格式, 也可采用 InfluxDB 的时间格式now() - 1d,需要注意的是在‘-’号左右都需要有空格,不然会提示语句出错:E7200: Invalid sql: Invalid time condition, out of time range.。
Query 语句不支持
select count(1) from stat_info where time >= '2017-09-19', 报错:E7200: Invalid sql, expected field argument in count(),field 必须指定。
Q10: 在初始化创建 Client 时,是否还要通过 SDK 函数生成配置?
需要通过
sdk.NewConfig()生成配置,将其置于配置文件当中,否则就会出错。
Q11: 错误定义是怎样的?
在 TSDB 中,在
tsdb/error.go里面定义了错误类型,在开发时,可以进行引用,也可以通过logger.Error()进行输出,通过对照编码表查找错误原因。
Q12: API 建立仓库、序列。
创建 Client 后,可以通过内置函数
CreateRepo()以及CreateSeries()进行创建,参数定义在tsdb/model.go中,包含了需要传入的参数以及返回数据类型结构。
Q13: API 数据查询。
可以通过
client.QueryPoints()进行查询,参数为 query 语句, 定义 query 语句传入即可进行数据查询,语法与 MySQL 以及 InfluxDB 大同小异。
返回类型包括:
QueryOutput{}
Result{}
Serie{}
在这里常用的只需要返回 Serie 即可,通过 index 访问数据,在这里需要注意 index out of range ,所以需要进行非空判断,以免造成程序出错。
Q14: API 数据写入
可以通过
client.WritePoints写入数据,需要注意区分 tags 与 fields , 通过参数 point 进行参数配置,包括 SeriesName(序列名)、tags、fields 。
Q15: 序列的字段类型定义。
字段类型在创建序列时并不需要定义,在第一次传入数据时,根据传入数据的类型即定义了序列的字段类型, 需要注意的是序列不支持复合类型,之后进行数据写入时,如果数据类型不一致,则会提示类型错误。
Q16: TSDB 存储期限
目前最大支持 30 天,在自定义存储期限时,也只允许定义在 30 天之内。
Q17: 数据查询经常出现偏差(统计时较为明显)
- 确定语句是否按照标准,有一些语法与其他数据库不一致;
- 字段名称是否是 tsdb 关键字,如果是,需要通过双引号;
- 如果使用了 distinct ,需要考虑字段为空的情况;
- 如果使用了 order by 语句,需要考虑字段是否是 tag。
Q18: 有数据,但是查询语句没有结果。
Where field 查询的时候要注意存储的类型和你查询的类型是否一致。
Q19: 在 Grafana 里面 where 语句不能智能提示?
where 语句的下拉列表默认只智能提示 tag ,field 智能手动输入。
Q20: Grafana 的Dashboard支持分配给不同的组织吗?
不支持,智能导出某个Dashboard,然后在其他角色下重新导入。
Q21: Grafana 的数据源支持导出吗?
不支持,只能手动录入,同一个组织下可以共享数据源。
Q22: 统计指标多对页面加载有影响吗?
一个页面的指标项太多会影响到整体的加载性能的。
七牛 APM
iOS https://github.com/pre-dem/pre-dem-objc
android https://github.com/pre-dem/pre-dem-android
bugly 偏向于崩溃收集,七牛 APM 偏向于移动性能分析。
该部分暂未接入,暂无问题清单(还没有踩坑,以后再补吧)。
其他
- 七牛是支持子账号的,有需要的可以申请开通;
- 容器应用 Grafana 有自己的登录账号系统,Kibana 是用的七牛统一的账号鉴权体系;
- Safari 可能默认是阻止弹窗的,记得允许弹窗;
总结
- 简单
- 方便
- 好用
- 强大
扩展知识
可能会涉及到的知识点或开源组件,项目:
- InfluxDB
- OpenTSDB
- Grafana
- Kibana
- ElasticSearch
- logkit
- Nginx
- …
参考资料
茶歇驿站
一个可以让你停下来看一看,在茶歇之余给你帮助的小站。
这里的内容主要是后端技术,个人管理,团队管理,以及其他个人杂想。